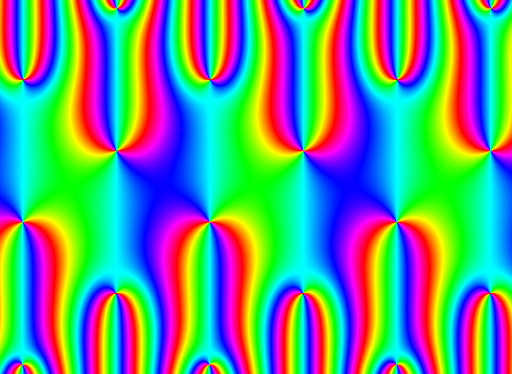
私はニュートン法のヤコビシータ関数のフラクタルを生成しようとしてきました。mpmathでの試行には長い時間がかかるため、Cでコーディングしてみました。
次の画像を生成するために使用されるソースは次のとおりです。http://owen.maresh.info/allegra.cであり、 gcc allegra.c -o allegra -lmでコンパイルされ、./allegra>jacobi.pnmとして呼び出される必要があります。

(ソース:maresh.info)
{kind=link}
だから:*評価をスピードアップする方法はありますか?これはこの画像を生成するのに30分以上の壁時間を要しましたか?(映画を作るために、これらの画像を異なる名前ですばやく作成できるようにしたいと思います)*シータ関数の定義に誤りがあることはわかっていますが、原因を特定するのに苦労しています。不連続性。
参考までに、この画像は、ϑ 3(z、0.001-0.3019 * i)で標準のニュートン法を実行して作成されました。