私はそれをたくさんグーグルで調べましたが、通常はそれができないことがわかりました。ここでハックの1つに出会いました:
http://www.bp-msbi.com/2011/04/ssrs-cascading-parameters-refresh-solved/
しかし、ssrs 2005 ではうまくいきませんでした。他の誰かが 2005 年に試したのではないかと思っています。
この記事によると、依存パラメーターは、最初のパラメーターの選択によってその値が無効になった場合にのみ更新されます。パラメータが変更されるたびに依存パラメータを無効にできる場合は、完全な更新を強制します。これを行う簡単な方法は、NEWID() T-SQL 関数で取得した GUID などの値を添付することです。
したがって、基本的には、2 つの実際のパラメーターの間に偽のパラメーターを導入したいと考えています。この偽のパラメーターは、その背後にある storedproc がその proc が呼び出されるたびに結果セットに GUID を追加するため、毎回新しい値を返すことになっています。そのため、他のパラメーターの完全な更新が強制されます。
今私が直面している主な問題は次のとおりです。
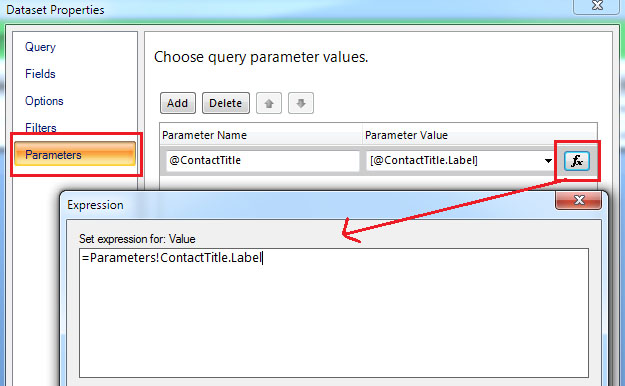
このフェイク パラメータのデフォルト値を設定します。使用可能な値については、偽のパラメーターの背後にある storedproc が実行され、次のような形式でデータが返されます: result1,result2_GUIDFROMSQL
クエリからデフォルト値を取得するように依頼すると、デフォルト値を設定するために同じstoredprocが再度呼び出されるようになりました。しかし、storedproc が再度実行されると、新しい GUID が取得されるため、古い値が見つからないため、必要に応じて設定されません。
導入されたパラメーターから次のパラメーターにこの GUID を渡すメカニズムを理解する必要があるだけです。
それが私が失敗しているところです。
私の問題は、データソースがこのクエリ文字列であるパラメーターを作成することで簡単に複製できます。
select getdate() id, @name nid
したがって、この場合、このパラメーターのデフォルト値を設定する方法。
{kind=link}