更新:私は解決策を見つけました。以下の私の答えを参照してください。
私の質問
このクエリを最適化してダウンタイムを最小限に抑えるにはどうすればよいですか?チケットの数が100,000から200万の範囲で、50を超えるスキーマを更新する必要があります。ticket_extraのすべてのフィールドを同時に設定することをお勧めしますか?私はここに私が見ていなかった解決策があると感じています。私はこの問題に1日以上頭をぶつけてきました。
また、最初はサブSELECTを使用せずに試しましたが、現在のパフォーマンスよりもはるかにパフォーマンスが低下しました。
バックグラウンド
実行する必要のあるレポート用にデータベースを最適化しようとしています。集計する必要のあるフィールドは計算に非常にコストがかかるため、このレポートに対応するために既存のスキーマを少し非正規化しています。数十の無関係な列を削除することで、チケットテーブルをかなり単純化したことに注意してください。
私のレポートは、作成時のマネージャーと解決時のマネージャーごとにチケット数を集計します。この複雑な関係をここに示します。

(出典:mosso.com)
{kind=link}
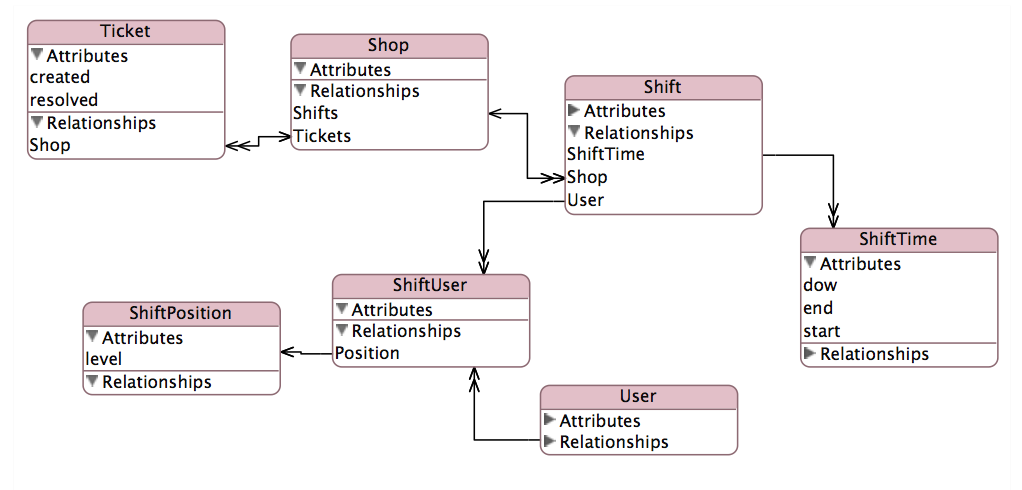
このオンザフライで計算するために必要な半ダースの厄介な結合を回避するために、次のテーブルをスキーマに追加しました。
mysql> show create table tickets_extra\G
*************************** 1. row ***************************
Table: tickets_extra
Create Table: CREATE TABLE `tickets_extra` (
`ticket_id` int(11) NOT NULL,
`manager_created` int(11) DEFAULT NULL,
`manager_resolved` int(11) DEFAULT NULL,
PRIMARY KEY (`ticket_id`),
KEY `manager_created` (`manager_created`,`manager_resolved`),
KEY `manager_resolved` (`manager_resolved`,`manager_created`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
現在の問題は、このデータをどこにも保存していないことです。マネージャーは常に動的に計算されました。同じスキーマを持つ複数のデータベースに数百万のチケットがあり、このテーブルにデータを入力する必要があります。できるだけ効率的な方法でこれを実行したいのですが、使用しているクエリを最適化できませんでした。
INSERT INTO tickets_extra (ticket_id, manager_created)
SELECT
t.id,
su.user_id
FROM (
SELECT
t.id,
shift_times.shift_id AS shift_id
FROM tickets t
JOIN shifts ON t.shop_id = shifts.shop_id
JOIN shift_times ON (shifts.id = shift_times.shift_id
AND shift_times.dow = DAYOFWEEK(t.created)
AND TIME(t.created) BETWEEN shift_times.start AND shift_times.end)
) t
LEFT JOIN shifts_users su ON t.shift_id = su.shift_id
LEFT JOIN shift_positions ON su.shift_position_id = shift_positions.id
WHERE shift_positions.level = 1
このクエリは、170万を超えるチケットを持つスキーマで実行するのに1時間以上かかります。これは、私が持っているメンテナンスウィンドウには受け入れられません。また、manager_resolvedフィールドの計算も処理しません。これを同じクエリに結合しようとすると、クエリ時間が成層圏にプッシュされるためです。私の現在の傾向は、それらを分離し、UPDATEを使用してmanager_resolvedフィールドに入力することですが、よくわかりません。
最後に、そのクエリのSELECT部分のEXPLAIN出力を次に示します。
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 167661
Extra:
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: su
type: ref
possible_keys: shift_id_fk_idx,shift_position_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: t.shift_id
rows: 5
Extra: Using where
*************************** 3. row ***************************
id: 1
select_type: PRIMARY
table: shift_positions
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 6
Extra: Using where; Using join buffer
*************************** 4. row ***************************
id: 2
select_type: DERIVED
table: t
type: ALL
possible_keys: fk_tickets_shop_id
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 5. row ***************************
id: 2
select_type: DERIVED
table: shifts
type: ref
possible_keys: PRIMARY,shop_id_fk_idx
key: shop_id_fk_idx
key_len: 4
ref: dev_acmc.t.shop_id
rows: 1
Extra:
*************************** 6. row ***************************
id: 2
select_type: DERIVED
table: shift_times
type: ref
possible_keys: shift_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: dev_acmc.shifts.id
rows: 4
Extra: Using where
6 rows in set (6.30 sec)
読んでくれてありがとう!