Linux システムでより効率的なパターン マッチングはどれですか?
3193 次
2 に答える
12
Bell Labs の Russ Cox は、2007 年にこれに関する素晴らしい記事を書きました。その中で彼は、
非決定論的有限オートマトンをgrep使用して Perl などよりも速度を向上させる方法を示しています。
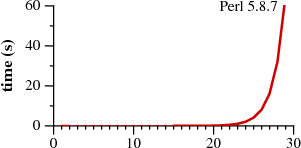
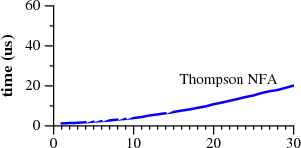
于 2013-01-22T08:36:52.563 に答える
0
私は私にとって最善の方法を見つけました。
以前は、何千もの要素の配列があり、別の何千もの要素のリストを grep して、配列から追加情報を取得していました。
ここで、配列をハッシュの配列に一度入れてから、毎回非常に迅速にデータを取得します。
だった:
@ua1 = grep /$ip/, @ua;
今:
$ua1[0] = $adrs{$ip};
于 2015-06-25T11:44:20.087 に答える