私はこれに数時間苦労してきました.
私たちの課題は、二分木を読み込んで保存することです。これは次のような形式で与えられます: ( (root) (left_subtree) (right_subtree))
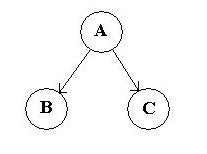
一致する括弧の各セットはツリーを表し、最初のものはルート、次は左のサブツリー、次に右のサブツリーです。サブツリーが葉の場合、括弧で囲む必要はありませんが、括弧で囲むことができます。これが何を意味するのかを明確にするために、次の例を参照してください。これらはすべて、コード ブロックの下に描かれているツリーの有効な表現です。
(A B C)
(A (B) C)
(A B (C))
((A) (B) (C))

(出典: otterbein.edu )
{kind=link}
定義の再帰的な性質をもう少しよく示す、より複雑な例として、次のツリーの可能な文字列の 1 つを次に示します。
(F(B A (D C E)) (G () (I (H))))
F の右サブツリー [つまり、"(G () (I (H)))"] では、空の左の子を示すために G の後に "()" が必要であることに注意してください。 G ["(I (H))"] は、より単純に "(IH)" と表すこともできます。

この入力からツリーを構築するために不可欠な関数を除いて、バイナリ ツリー クラス (および対応する TreeNode クラス) を完成させましたが、文字列を正確に解析する方法について頭を悩ませているようには見えません。私はそれを行う方法についての一般的な考えを持っています-少なくとも、再帰がどのように機能するか-しかし、問題をより小さな部分に分解する方法を正確に理解することは私の頭を悩ませています。
//pseudocode musings
TreeNode* Tree::buildFromString(string s){
TreeNode* temp = NULL
if ( the string doesn't represent an empty tree )
temp = new TreeNode
temp->data = part of s representing root
temp->leftChild = buildFromString( part of s representing left subtree)
temp->rightChild = same as above, but with right subtree
}
return temp;
私は再帰自体に問題を抱えているわけではありません。それは理にかなっています。頭の中で大まかにトレースするのはそれほど難しくありません。基本的なケースはうまくいきます - リーフノードに到達したら、再帰から抜け出して呼び出しに戻り、戻るときにサブツリーをリンクします。
しかし、問題をコード内の小さな断片に分割する方法がわかりません。これは明らかに再帰の要点です。元の部分文字列を作成して再帰呼び出しに渡したいのですが、適切な部分を取得する方法について頭を悩ませているようには見えません。
アイデアはありますか?