特定の要因の発生回数をレンダリングする ggplot2 ベースのヒートマップがあります。ただし、異なるデータセットには、いくつかの要因のインスタンスがない場合があります。つまり、それぞれのヒートマップは異なって見えます。並べて比較しやすくするために、不足しているレベルを追加したいと思います。残念ながら、私は成功していません。
したがって、次のようなデータがあります。
> head(numRules)
Job Generation NumRules
1 0 0 2
2 0 1 1
3 0 2 1
4 0 3 1
5 0 4 1
6 0 5 1
> levels(factor(numRules$NumRules))
[1] "1" "2" "3"
次のコードを使用して、すべてのジョブの世代ごとのルール数をカウントする適切なヒートマップをレンダリングします。
ggplot(subset(numRules, Generation < 21), aes(x=Generation, y=factor(NumRules))) +
stat_bin(aes(fill=..count..), geom="tile", binwidth=1, position="identity") +
ylab('Number of Rules')
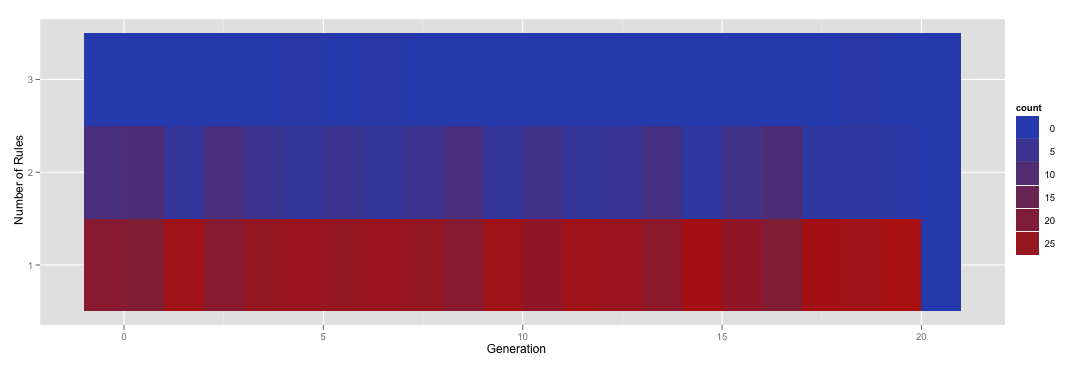
つまり、ヒート マップは、ほとんどの場合、実行には特定の世代に対して 1 つのルールしかないことを示していますが、2 つ取得することもあれば、まれに 3 つ取得することもあります。
現在、まったく異なる一連の実行では、特定の世代に対して実際にはゼロのルールがある場合があります。ただし、一方のヒート マップの y 軸のルール数は [1,3] で、もう一方のルールの数は [0,2] である可能性があるため、並べて比較すると少し混乱します。私がやりたいのは、ヒートマップを標準化して、ルールの数に関係なく、すべての因子レベルが (0,1,2,3) になるようにすることです。たとえば、上記のヒート マップを再レンダリングして、その特定のデータ フレームにそのインスタンスがない場合でも、ゼロ ルールの行を含めたいと考えています。
私はこれを、ブレークやスケールの設定などを含むさまざまな R の呪文で打ち負かしましたが、役に立ちませんでした。私の直感では、これには簡単な解決策がありますが、見つけることができません。
更新:
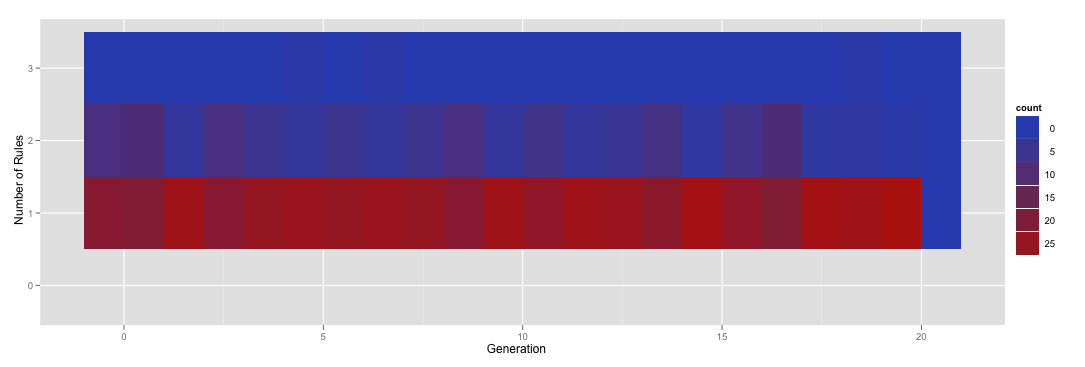
への呼び出しでレベルを手動で指定するとfactor、ゼロ ルールの行が追加されます。
ggplot(subset(numRules, Generation < 21), aes(x=Generation, y=factor(NumRules,levels=c("0","1","2","3")))) + stat_bin(aes(fill=..count..), geom="tile", binwidth=1, position="identity") + ylab('Number of Rules')
これはこれをもたらします。
残念ながら、ご覧のとおり、この新しい行は適切に色付けされていません。そこに着く!


{kind=link}
{kind=link}