バージョン履歴でアソシエーション マイニングを実行しようとしています。mysql にトランザクション データがあります。Weka apriori アルゴリズムには、特定の形式の arff または csv ファイルが必要です。項目ごとに列が必要です。値は、トランザクション内の各アイテムに対して TRUE または FALSE として指定されます。Weka InstanceQuery を使用してこのファイルを作成する方法を探しています。また、トランザクション データが膨大な場合のオプションは何ですか。
4536 次
2 に答える
1
2 番目の部分についてはお答えできます。トランザクション データが膨大な場合のオプションです。Weka は優れたソフトウェアですが、アプリオリな実装は非常に遅いです。http://fimi.ua.ac.be/src/での実装をお勧めします(Ferenc Bodon のリストの最初のものを使用しました)。
Bodon の実装では、Weka が使用するハッシュテーブルの代わりに Trie データ構造を使用します。このため、私は自分の仕事で、Bodon の実装が 1 時間以内に完了するのに Weka は 3 日かかることを発見しました (そうです、違いはこれほど大きいです!!)。
さらに、Bodon の実装では単純な入力形式が使用されています。つまり、トランザクションごとに 1 行で、アイテムはスペースで区切られています。
于 2013-03-29T00:04:10.897 に答える
0
FPGrowth または Apriori の高速な Java 実装が必要な場合は、私のプロジェクト SPMF をご覧ください。SPMF での FPGrowth の実装は、一部のデータセットで Weka の実装を最大 2 桁上回っています。たとえば、次のパフォーマンス比較を確認できます。
http://www.philippe-fournier-viger.com/spmf/performance/chess_fpgrowth_spmf_vs_weka.png
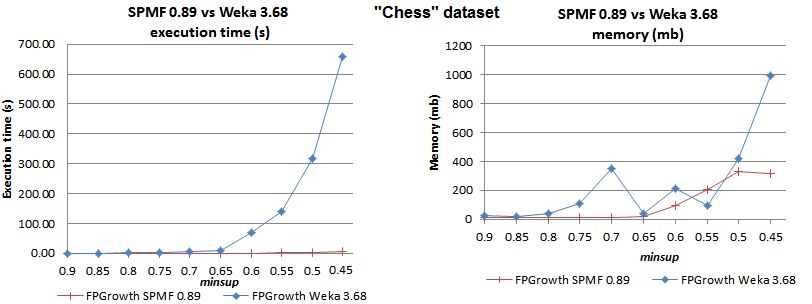{kind=link}
これはメイン プロジェクトの Web ページです。
http://www.philippe-fournier-viger.com/spmf/index.php
さらに、SPMF は、アイテムセット マイニング、アソシエーション ルール マイニング、シーケンシャル パターン マイニングなどに 50 以上のアルゴリズムを提供することに注意してください。また、SPMF の GUI バージョンは、Weka で使用される ARFF 形式もサポートしています。
于 2013-06-06T03:19:52.700 に答える