BeautifulSoup のような HTML パーサーは、入力 HTML 構造を反映したオブジェクト モデルが必要であると想定します。しかし、時々 (この場合のように) そのモデルは助けになる以上に邪魔になります。Pyparsing には、生の正規表現を使用するよりも堅牢な HTML 解析機能がいくつか含まれていますが、それ以外は同様の方法で機能し、関心のある HTML のスニペットを定義し、残りを無視することができます。以下は、投稿された HTML ソースを読み取るパーサーです。
from pyparsing import makeHTMLTags,withAttribute,Suppress,Regex,Group
""" looking for this recurring pattern:
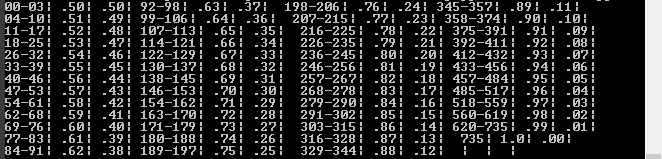
<td valign="top" bgcolor="#FFFFCC">00-03</td>
<td valign="top">.50</td>
<td valign="top">.50</td>
and want a dict with keys 0, 1, 2, and 3 all with values (.50,.50)
"""
td,tdend = makeHTMLTags("td")
keytd = td.copy().setParseAction(withAttribute(bgcolor="#FFFFCC"))
td,tdend,keytd = map(Suppress,(td,tdend,keytd))
realnum = Regex(r'1?\.\d+').setParseAction(lambda t:float(t[0]))
integer = Regex(r'\d{1,3}').setParseAction(lambda t:int(t[0]))
DASH = Suppress('-')
# build up an expression matching the HTML bits above
entryExpr = (keytd + integer("start") + DASH + integer("end") + tdend +
Group(2*(td + realnum + tdend))("vals"))
このパーサーは、一致するトリプルを選択するだけでなく、開始と終了の整数と実数のペアも抽出します (また、解析時に文字列から整数または浮動小数点数に変換されます)。
表を見ると、実際には 700 のようなキーを取得し、値のペア (0.99、0.01) を返すルックアップが必要だと思います。700 は 620 ~ 735 の範囲にあるからです。このコードは、ソース HTML テキストを検索し、一致したエントリを反復処理して、キーと値のペアを辞書ルックアップに挿入します。
# search the input HTML for matches to the entryExpr expression, and build up lookup dict
lookup = {}
for entry in entryExpr.searchString(sourcehtml):
for i in range(entry.start, entry.end+1):
lookup[i] = tuple(entry.vals)
そして、いくつかのルックアップを試してみましょう:
# print out some test values
for test in (0,20,100,700):
print (test, lookup[test])
プリント:
0 (0.5, 0.5)
20 (0.53, 0.47)
100 (0.64, 0.36)
700 (0.99, 0.01)
{kind=link}