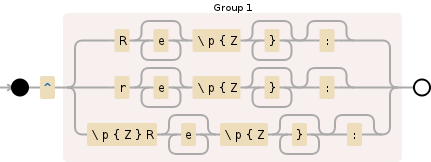
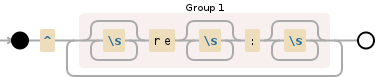
1 つ以上の sequence で始まる文字列があります"Re:"。これ"Re:"は、たとえば、任意の組み合わせにすることができます。Re<any number of spaces>:、re:、re<any number of spaces>:、RE:、RE<any number of spaces>:など
文字列 のサンプル シーケンス : のRe: Re : Re : re : RE: This is a Re: sample string.
すべての出現箇所を識別して削除する Java 正規表現を定義したいと考えていますがRe:、文字列内に出現するものではなく、文字列の先頭にあるもののみを削除します。
したがって、出力は次のようThis is a Re: sample string.
になります。
String REGEX = "^(Re*\\p{Z}*:?|re*\\p{Z}*:?|\\p{Z}Re*\\p{Z}*:?)";
String INPUT = title;
String REPLACE = "";
Pattern p = Pattern.compile(REGEX);
Matcher m = p.matcher(INPUT);
while(m.find()){
m.appendReplacement(sb,REPLACE);
}
m.appendTail(sb);
私はp{Z}空白を一致させるために使用しています(Java正規表現では識別されないため、このフォーラムのどこかでこれを見つけました\s)。
このコードで私が直面している問題は、検索が最初の一致で停止し、while ループをエスケープすることです。