この正規表現は、html の開始タグと一致するはずです。
var results = html.match(/<(\/?)(\w+)([^>]*?)>/);
最初に をキャプチャする必要があることがわかります<が、このキャプチャが何を(\/?)達成するのか混乱しています。>= 0回([^>]*?)>を除くすべての文字を検索するという推論は正しいですか? >もしそうなら、なぜ(\w+)捕獲が必要なのですか?の範囲に入らないか[^>]*?
この正規表現は、html の開始タグと一致するはずです。
var results = html.match(/<(\/?)(\w+)([^>]*?)>/);
最初に をキャプチャする必要があることがわかります<が、このキャプチャが何を(\/?)達成するのか混乱しています。>= 0回([^>]*?)>を除くすべての文字を検索するという推論は正しいですか? >もしそうなら、なぜ(\w+)捕獲が必要なのですか?の範囲に入らないか[^>]*?
トークンごとに取得します。
/正規表現リテラルを開始<リテラルに一致<(\/?)?0 または 1 ( ) リテラルに一致/し、\(\w+)1 つ以上の「単語文字」に一致([^>]*?)*?lazily*ではないものの0 個以上 ( ) に一致>>リテラルに一致>/正規表現リテラルを終了怠惰* - 「?」を追加 つまり、正規表現は前のトークンと最小回数一致します。ドキュメントを参照してください。
したがって、基本的に、この正規表現は「<」に一致し、その後に「/」が続く可能性があり、その後に任意の数の文字、数字、またはアンダースコアが続き、その後に ">" 以外が続き、最後に ">" が続きます。 .
そうは言っても、 と の間に(\w+)少なくとも 1 つの単語文字があることを保証するため、トークンは冗長ではありません。<>
正規表現を使用して HTML を解析しようとするのは、一般的に悪い考えであることに注意してください。
debuggex の機能を使用してイメージを生成します :)
<(\/?)(\w+)([^>]*?)>
このように評価されます
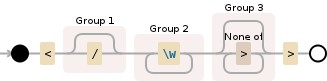
ご覧のとおり、HTML タグ (開始タグと終了タグ) に一致します。正規表現には、次をキャプチャする 3 つのキャプチャ グループが含まれています。
(\/?)の存在/(存在する場合は終了タグです)(\w+)タグの名前([^>]*?)タグが閉じるまでの他のすべて (属性など)このように一致し<a href="#">ます。興味深いことに、属性内<a data-fun="fun>nofun">で停止するため、正しく一致しません。(私は思う)が属性値で有効ですが。>data-fun>
もう 1 つの面白い点は、タグ名キャプチャでは、理論的に有効な XHTML タグがすべてキャプチャされないことです。XHTML が許可されますLetter | Digit | '.' | '-' | '_' | ':' | ..(ソース: XHTML 仕様)。ただし、 、、および と(\w+)は一致しません。架空のタグは、この正規表現では一致しません。ただし、これは実際の生活に影響を与えるべきではありません。.-:<.foobar>
RgExes を使用して HTML を解析するのは危険であることがわかります。HTML パーサーを使用した方がよい場合があります。
最後の質問に答えるために、冗長ではありません(\w+)。([^>]*?)どちらも式で重要な機能を果たします。
この式は、開始タグまたは終了タグを見つけます。
(\/?)a に一致します/が、?によりオプションになります。
(\w+)ここでタグ名と一致することを意図した、単語の文字と一致します。
([^>]*?)属性を一致させることを目的としています。
したがって、文字列がある場合<div class="text">、
(\w+)式の が一致しdiv、([^>]*?)が一致しますclass="text"
デモ (javascript ではなく Ruby ですが、違いはありません): http://www.rubular.com/r/bhw2O28qUr
要約すると、終了タグをキャプチャすることです。