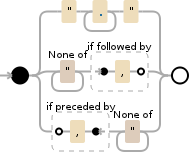
説明
分割を使用する代わりに、単純に一致を実行して、見つかったすべての一致を処理する方が簡単だと思います。
この式は次のようになります。
- サンプル テキストをカンマ区切りで分割します
- 空の値を処理します
- 二重引用符がネストされていない場合、二重引用符で囲まれたコンマは無視されます
- 戻り値から区切りコンマを削除します
- 戻り値から周囲の引用符を削除します
正規表現: (?:^|,)(?=[^"]|(")?)"?((?(1)[^"]*|[^,"]*))"?(?=,|$)

例
サンプルテキスト
123,2.99,AMO024,Title,"Description, more info",,123987564
Java 以外の式を使用した ASP の例
Set regEx = New RegExp
regEx.Global = True
regEx.IgnoreCase = True
regEx.MultiLine = True
sourcestring = "your source string"
regEx.Pattern = "(?:^|,)(?=[^""]|("")?)""?((?(1)[^""]*|[^,""]*))""?(?=,|$)"
Set Matches = regEx.Execute(sourcestring)
For z = 0 to Matches.Count-1
results = results & "Matches(" & z & ") = " & chr(34) & Server.HTMLEncode(Matches(z)) & chr(34) & chr(13)
For zz = 0 to Matches(z).SubMatches.Count-1
results = results & "Matches(" & z & ").SubMatches(" & zz & ") = " & chr(34) & Server.HTMLEncode(Matches(z).SubMatches(zz)) & chr(34) & chr(13)
next
results=Left(results,Len(results)-1) & chr(13)
next
Response.Write "<pre>" & results
Java 以外の式を使用して一致します
グループ 0 はコンマを含む部分文字列全体を取得します
グループ 1 が使用されている場合は引用符を取得します
グループ 2 はコンマを含まない値を取得します
[0][0] = 123
[0][1] =
[0][2] = 123
[1][0] = ,2.99
[1][1] =
[1][2] = 2.99
[2][0] = ,AMO024
[2][1] =
[2][2] = AMO024
[3][0] = ,Title
[3][1] =
[3][2] = Title
[4][0] = ,"Description, more info"
[4][1] = "
[4][2] = Description, more info
[5][0] = ,
[5][1] =
[5][2] =
[6][0] = ,123987564
[6][1] =
[6][2] = 123987564