あなたの式は最初のドットに一致し、ドット.*?にも一致します。したがって、あなたShyam and you...はマッチとして得ます。ドット以外のすべての文字に一致するように変更(.*?are.*?)してみてください。([^\\.]*?are[^\\.]*?)
\s*([^\.]*are[^\.]*)式を(ここでは非 Java 表記)に単純化することもできることに注意してください。これは同じ結果になりますが、 にも一致し"You are Shyam. You are Mike."ます。
この式は、間に「are」があり、その前にオプションの空白があるドット以外の任意の文字列に一致します。これはare単独でも一致するため、 に変更[^\.]*することをお勧めします[^\.]+。
編集:
更新された例を説明するために、次の式を試すことができます (内訳は次のとおりです)。
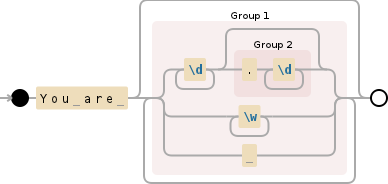
\s*((?:[^\.]|(?:\w+\.)+\w)*are.*?)(?:\.\s|\.$)
入力:I am here. You are almost 2.3 km away from home. You are Mike. You are 2. 2.3 percent of them are 2.3 percent of all. Sections 2.3.a to 2.3.c are 3 sections. This is garbage.
出力: You are almost 2.3 km away from home, You are Mike, You are 2, 2.3 percent of them are 2.3 percent of all,Sections 2.3.a to 2.3.c are 3 sections
いくつかの注意: これには、各文がドットで終わる必要があり (これは に置き換えることで変更できます\.\s|\.$) [.!?]\s|[.!?]$、各区切りドットの後に空白または入力の終わりが続き、一致しないYou are J. J. Abramsか、2.a
その場合、特に「単純な」正規表現では、コンピューターが文の終わりを判断するのが非常に難しいことに注意してください。
式の内訳:
\s*先頭の空白はグループの一部ではありません。それ以外の場合は必要ありません((?:[^\.]|(?:\w+\.)+\w)*are.*?)are前後の追加テキスト
を含む、キャプチャされたグループ
(?:[^\.]|(?:\w+\.)+\w)[^\.]ドット以外の文字 ( ) または ( )の任意のシーケンスに一致する非キャプチャ グループ(のショートカットとして) 間に単一のドットがある ( 、非キャプチャ)|単語文字のシーケンス\w[a-zA-Z0-9_](?:\w+\.)+\w).*?任意の文字シーケンスですが、最長シーケンスではなく最短シーケンスに一致する遅延修飾子を使用します (それがないと、次の部分はあまり意味がありません)
(?:\.\s|\.$)キャプチャされたグループの後に続く必要がある非キャプチャ グループ。ドットの後に空白が続く ( \.\s) または ( )|入力の末尾のドット( ) と一致する必要があります。\.$
編集2:
(A|B)*グループなしで完全にテストされていないバージョンを次に示します。
\s*([^.]*(?:(?:\w+\.)+\w+[^.]*)*are.*?)(?:[.!?]\s|[.!?]$)
基本的(?:[^\.]|(?:\w+\.)+\w)*に は に置き換えられました[^.]*(?:(?:\w+\.)+\w+[^.]*)*。これは、「ドット以外の文字の任意のシーケンスの後に、単語文字で囲まれたドットで構成される任意の数のシーケンスが続き、その後にドット以外の文字の任意のシーケンスが続く」ことを意味します。;)