文字列が '#' で始まるかどうかを確認するにはどうすればよいですか?
#path /var/dumpfolder
awkを試しました
awk -F '' '{print $1}'
もっと良い方法はありますか?
私はまだあなたが何をしようとしているのか理解できませんが、あなたのタグにはbashがあるので、ここに bash ソリューションがありますcheck if string starts with '#'
string='#path /var/dumpfolder'
if [[ $string == \#* ]]; then
echo 'yes'
else
echo 'no'
fi
また:
if [[ ${string:0:1} == '#' ]]; then
echo 'yes'
else
echo 'no'
fi
#文字を削除する場合は、次を使用します。
echo "${string#\#}" # prints 'path /var/dumpfolder'
#これにより、文字が存在する場合は削除されます。存在しない場合、文字列はそのまま残ります。
先頭にスペースがある場合がある場合は、regexp を使用します。
if [[ $string =~ ^[[:space:]]*\#.*$ ]]; then
echo "${string#*\#}"
else
echo "$string"
fi
^\s*[#](.*)$
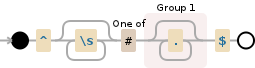
ここに正規表現があります.....それがあなたが探しているものなら.
^文字列の開始を示します\s*#の前にスペースがある可能性がある場合に対処するためのもう1つのスペースを意味します[#]または単に#機能し、最初の文字が # であることを確認します(.*)すべて (ほとんど) の文字を取得し、それらをキャプチャ グループに投入します$文字列の最後で停止しますこれは、コード内の # とコメントの前のスペースを削除するために機能するはずです
sed 's/\^\s*[#](.*)$/\1/'
私は基本的に、文字列がコメントされているかどうかを確認したいので、そのコメント「#」を文字列から削除して保持したいと考えています。はい、コメントなしのメッセージまたは保存文字列。
それで
sed 's/^\s*#*//'
例(ファイル付き):
kent$ cat f
#c1
#c2
foo
bar
kent$ sed 's/^\s*#*//' f
c1
c2
foo
bar
#pathファイル内のまたはpath(# なしで) パターンを検索するだけの場合は、次のようにします。
grep -E '^#?path' file
正確に見つける#pathには、追加しないでください?:
grep -E '^#path' file
より明白なのはスペースを追加することですが、セパレーターをタブにすることもできます:
grep -E '^#path ' file