ブラウザー (FireFox) でページのソースを表示し (View->Page Source)、それをコピーして HTML エディターに貼り付けると、ほとんど同じページが表示されます (この例では www.google.com)。ブラウザに表示されるとおりです。しかし、このコードを介して (Google の App Engine を介して) HTML ソースを取得すると、
from google.appengine.api import urlfetch
url = "http://www.google.com/"
result = urlfetch.fetch(url)
if result.status_code == 200:
print result.content
それをコピーして HTML エディタに貼り付けると、ページがまったく異なって見えます。なぜそうなのですか?コードに何か問題がありますか?
+++++++++++++++++++++++++++++++
ファローアップ:
この瞬間 (正確には 2009 年 12 月 13 日日曜日午後 1 時 1 分、GMT) に、2 つのコメント質問 ( AaronとChristian P.から) とAlex Martelliから 1 つの回答を受け取りました。
AaronとChristian P.の両方が、Fire-Fox で取得したソースと Google-App-Engine で取得したソースを同じ HTML エディターで表示した場合の実際の違いについて質問しています。
ここに私もスクリーンショットをアップロードしました:
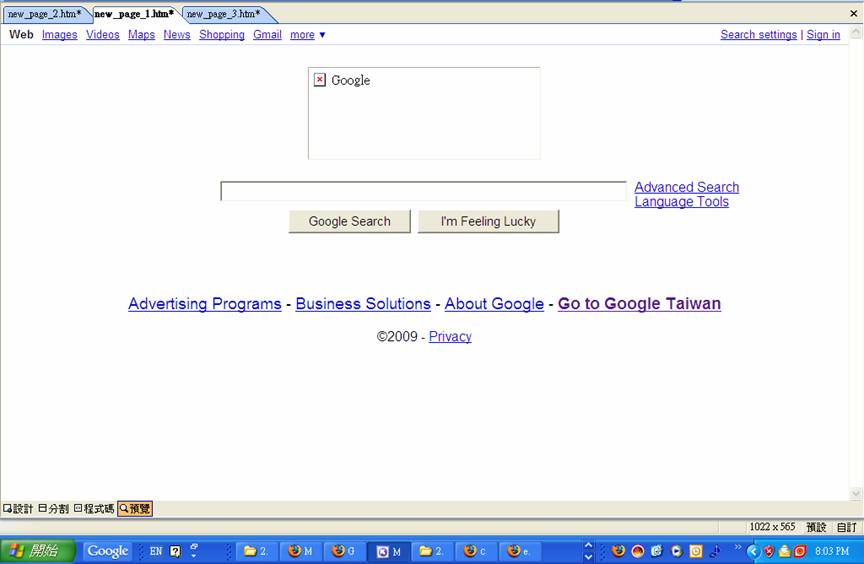{kind=link}
もう 1 つは、Google-App-Engine で取得したソースを示しています
{kind=link}
「MS Front Page」エディターで両方を表示した場合。
非常に明白な違いの 1 つは、エンコーディングの違いです。Fire-Fox コードではすべてが英語で表示されますが、Google-App-Engine コードでは代わりに多くのさまざまな記号が表示されます。
もう 1 つの違いは、Google App Engine コードのページの上部にある追加の行です。これは、 Alex Martelliが彼の回答で話していたことだと思います (「... fetch-and-print アプローチには、メタデータも含まれます...」)。
もう 1 つの小さな違いは、Google 画像のボックスが 1 つのコードでは複数のボックスに分割されているのに対して、別のコードでは完全なままであることです。
Alex Martelliは、私がこのコードを使用することを提案しました (私が彼を正しく理解していれば):
from google.appengine.api import urlfetch
url = "http://www.google.com/"
result = urlfetch.fetch(url)
if result.status_code == 200:
print "content-type: text/plain"
print
試してみましたが、この場合は何も表示されません。
ご回答いただきありがとうございます。引き続きご回答ください。この問題が最終的に解決されることを心から願っています。
+++++++++++++++++++++++++++++++
ファローアップ:
さて、問題は解決しました。
私はAlex Martelliの指示に十分な注意を払うことができなかったため、間違ったコードを思いつきました。これが彼の正しいものです:
from google.appengine.api import urlfetch
url = "http://www.google.com/"
result = urlfetch.fetch(url)
if result.status_code == 200:
print "content-type: text/plain"
print
print result.content
このコードは必要なものを正確に表示します。ページの上部に追加の行はありません。
うーん、まだ奇妙な記号が表示されますが、これはおそらく Google の問題であることがわかりました。問題は、私は現在台湾にいて、Google はそれを認識しているようで、自動的に www.google.com (英語) から www.google.com.tw (中国語) に切り替えますが、これは、 私は、すでに別のトピックだと思います。
ここで回答してくれたすべての人に感謝します。