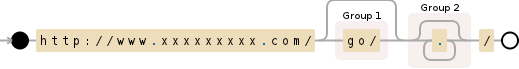正規表現モジュールを使用して、.csv ファイルから URL の一部を削除し、選択したチャンクを出力として返す小さなコードを作成しようとしています。セクションが .com/go/ で終わる場合、「go」後にコンテンツを返したいと思います。コードは次のとおりです。
import csv
import re
with open('rtdata.csv', 'rb') as fhand:
reader = csv.reader(fhand)
for row in reader:
url=row[6].strip()
section=re.findall("^http://www.xxxxxxxxx.com/(.*/)", url)
if section==re.findall("^go.*", url):
section=re.findall("^http://www.xxxxxxxxx.com/go/(.*/)", url)
print url
print section
そして、ここにいくつかのサンプル入出力があります:
- 例 1
- 入力:
http://www.xxxxxxxxx.com/go/news/videos/ - 出力:
news/videos
- 入力:
- 例 2
- 入力:
http://www.xxxxxxxxx.com/new-cars/ - 出力:
new-cars
- 入力:
ここで何が欠けていますか?