自分で見てください。今後の参考のために、グーグルで検索できます:
Java LinkedHashMap ソース
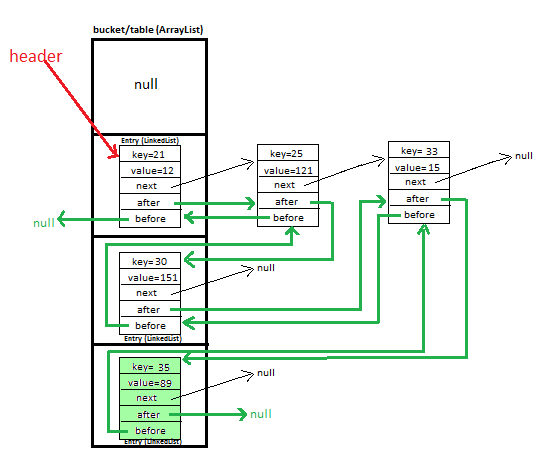
HashMapは衝突を処理するために aを使用しますが、とLinkedListの違いは予測可能な反復順序があることです。これは、追加の二重リンク リストによって実現され、通常はキーの挿入順序が維持されます。例外は、キーが再挿入された場合です。この場合、キーはリスト内の元の位置に戻ります。 HashMapLinkedHashMapLinkedHashMap
参考までに、 a を反復する方が a をLinkedHashMap反復するよりも効率的ですHashMapが、LinkedHashMapメモリ効率は低くなります。
上記の説明から明確でない場合、ハッシュ プロセスは同じであるため、通常のハッシュの利点が得られますが、二重にリンクされたリストを使用しているため、上記の反復の利点も得られます。オブジェクトの順序を維持しEntryます。これは、あいまいな場合に備えて、衝突のハッシュ中に使用されるリンク リストとは無関係です。
編集: (OPのコメントに応じて):
AHashMapは配列に支えられており、一部のスロットにEntryは衝突を処理するためのオブジェクトのチェーンが含まれています。すべての (キー、値) ペアを反復処理するには、配列内のすべてのスロットを通過してから、LinkedLists;を通過する必要があります。したがって、全体の時間は容量に比例します。
を使用する場合LinkedHashMap、双方向リンク リストをトラバースするだけでよいため、全体の時間はサイズに比例します。