私が得ようとしている結果に近づくのを手伝ってくれる人はいますか?
画像をスキャンした後、OCR の結果として次の文字列が返されます。
7915-03226E3058-089179 2013 年 9 月 4 日 (水) の抽選に幸運を祈ります あなたの番号 A06 09 26 40 43 45 B 06 14 18 28 43 48 C 02 16 22 34 39 42 111111 II 111111111 = 11111110 x1111 の抽選に当たります。 3.00 先週、ロトの当選者数は 700,000 人を超えました! 7915-032268058-089179 013779 用語。46377201 E - •I ボックスに入力してチケットを無効にします
"A06 09 26 40 43 45"、"B 06 14 18 28 43 48"、およびの値を取り出そうとしています。"C 02 16 22 34 39 42"
"A"正直に言うと、 、"B"、およびは必要ありません"C"。それぞれの後に12個の数字だけが必要です。
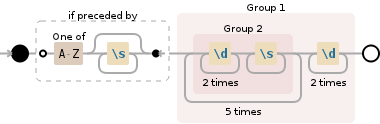
私はの正規表現を持っています
[A-Z](\W*\d{2}){6}
しかし、それは私が望まない余分な情報を引き出しています: http://regexr.com?372b7
誰かに近づく方法を提案できますか?チケット番号を取得するためのより良い方法はありますか?