そこで、これを使ってコンピュータをプロキシにするプログラムを作ろうとしています。gzip/deflate ページを除いて、すべて正常に動作します。
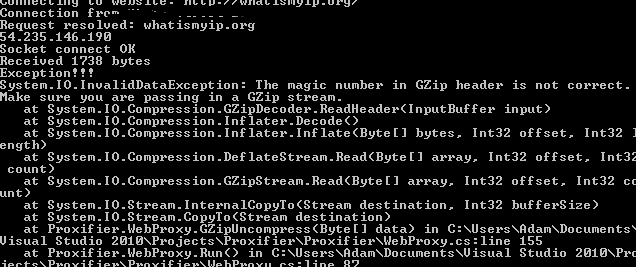
解凍しようとすると、GzipHeader のマジック ナンバーが正しくないことを示す InvalidDataException が発生します。
私はこの機能を使用します:
private byte[] GZipUncompress(byte[] data)
{
using (var input = new MemoryStream(data))
{
input.Seek(0, SeekOrigin.Begin);
using (var gzip = new GZipStream(input, CompressionMode.Decompress))
using (var output = new MemoryStream())
{
output.Seek(0, SeekOrigin.Begin);
gzip.CopyTo(output);
return output.ToArray();
}
}
}
データを解凍します。エラー:

(出典:gyazo.com)
{kind=link}
どんな助けでも大歓迎です。
編集:私はどこかに着いたようです!
usr が示唆したように、本文を取得して解凍する HTTP パーサーを作成する必要があります。
解析前: http://pastebin.com/Cb0E8WtT
解析後: http://pastebin.com/k9e8wMvr
これは、ボディに到達するために使用する方法です。
private byte[] HTTParse(byte[] data)
{
string http = ascii.GetString(data);
char[] lineBreak = crlf.ToCharArray();
string[] parts = http.Split(lineBreak);
List<byte> res = new List<byte>();
for (int i = 1; i < parts.Length; i++)
{
if (i % 2 == 0)
{
Regex r = new Regex(@"(.)*: (.)*");
Regex htt = new Regex(@"HTT(.)*/(.)*.(.)* d{1,50} (.)*");
if (!r.IsMatch(parts[i]) && !htt.IsMatch(parts[i]))
{
//Console.WriteLine("[TEST] " + parts[i]);
res.AddRange(ascii.GetBytes(parts[i]));
res.AddRange(ascii.GetBytes("\r\n"));
}
}
}
return res.ToArray();
}
ただし、「GZip ヘッダーのマジック ナンバーが正しくありません。GZip ストリームを渡していることを確認してください」というエラーが表示されます。
編集 (2): hereから回答をコピーした後、本文を正常に解凍することができました。
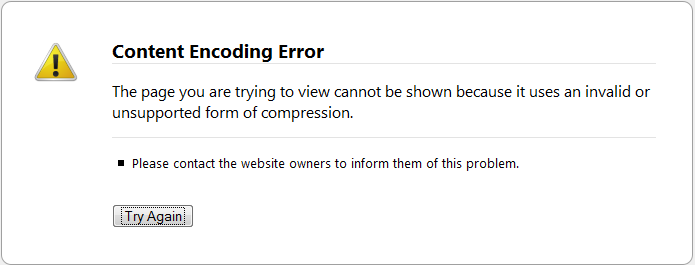
新しい問題: Firefox。

(出典:gyazo.com)
{kind=link}
gzipページを解凍する必要があるかどうかさえわかりません..
どこで間違ったのですか?