ユースケースは、固定文字列のように他の文字列の大規模なセットをランク付けするオートコンプリート オプションです。
各オプションソリューションを最初からやり直すよりも優れた仕事をすることができる、DFA RegEx のような何かのろくでなし化はありますか?
この質問をした人は解決策を知っているようですが、情報源を挙げていません。
(ps「このリンクを読む」タイプの回答歓迎。)
ユースケースは、固定文字列のように他の文字列の大規模なセットをランク付けするオートコンプリート オプションです。
各オプションソリューションを最初からやり直すよりも優れた仕事をすることができる、DFA RegEx のような何かのろくでなし化はありますか?
この質問をした人は解決策を知っているようですが、情報源を挙げていません。
(ps「このリンクを読む」タイプの回答歓迎。)
私は最近、このようなことをしました。残念ながらクローズドソースです。
解決策は、レーベンシュタイン オートマトンを書くことです。ネタバレ:それはNFAです。
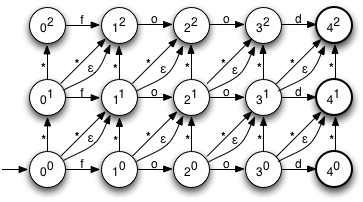
多くの人は、NFA のシミュレーションは指数関数的であるとあなたに納得させようとしますが、そうではありません。NFA から DFA を作成することは指数関数的です。シミュレーションは単なる多項式です。多くの正規表現エンジンは、これに基づく準最適なアルゴリズムで書かれています。
NFA シミュレーションは、n サイズの文字列と m 状態の場合、O(n*m) です。または、遅延してDFAに変換する(そしてキャッシュする)場合、O(n)は償却されます。
残念ながら、複雑なオートマトン ライブラリを処理する必要があるか、大量のコードを記述する必要があります (私が行ったように)。