次の問題を解決するために、適度なスペース要件で高速なアルゴリズムを見つけようとしています。
DAG の各頂点について、DAG の推移閉包の入次数と出次数の合計を求めます。
この DAG を考えると:
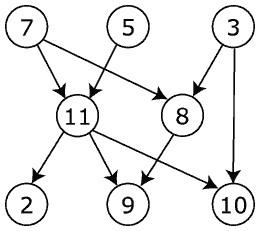
次の結果が期待されます。
Vertex # Reacability Count Reachable Vertices in closure
7 5 (11, 8, 2, 9, 10)
5 4 (11, 2, 9, 10)
3 3 (8, 9, 10)
11 5 (7, 5, 2, 9, 10)
8 3 (7, 3, 9)
2 3 (7, 5, 11)
9 5 (7, 5, 11, 8, 3)
10 4 (7, 5, 11, 3)
これは、推移閉包を実際に構築しなくても可能であるように思われます。この問題を正確に説明するものをネット上で見つけることができませんでした。これを行う方法についていくつかのアイデアがありますが、SO クラウドが何を思いつくかを見たかったのです。