与えられた単語の辞書と頭文字。単語に文字を連続して追加して、辞書内で可能な限り長い単語を見つけます。任意のインスタンスで、単語は辞書で有効な単語である必要があります。
例: a -> at -> cat -> cart -> chart ....
与えられた単語の辞書と頭文字。単語に文字を連続して追加して、辞書内で可能な限り長い単語を見つけます。任意のインスタンスで、単語は辞書で有効な単語である必要があります。
例: a -> at -> cat -> cart -> chart ....
強引なアプローチは、深さ優先検索を使用して、使用可能な各インデックスに文字を追加しようとすることです。
つまり、「a」から始めて、新しい文字を追加できる場所が 2 つあります。「a」の前または後ろ。以下のドットで表されます。
.a.
「t」を追加すると、3 つの位置ができます。
.a.t.
使用可能な各位置に 26 文字すべてを追加してみてください。この場合の辞書は、単純なハッシュテーブルにすることができます。途中に「z」を追加すると、ハッシュテーブルにない「azt」が得られるため、検索でそのパスを続行しません。
編集:Nick Johnsonのグラフは、すべての最大パスのグラフがどのように見えるかを知りました。ここに大きな (1.6 MB) 画像があります。
http://www.michaelfogleman.com/static/images/word_graph.png
編集:これはPythonの実装です。ブルート フォース アプローチは、実際には妥当な時間 (最初の文字によっては数秒) で実行されます。
import heapq
letters = 'abcdefghijklmnopqrstuvwxyz'
def search(words, word, path):
path.append(word)
yield tuple(path)
for i in xrange(len(word)+1):
before, after = word[:i], word[i:]
for c in letters:
new_word = '%s%s%s' % (before, c, after)
if new_word in words:
for new_path in search(words, new_word, path):
yield new_path
path.pop()
def load(path):
result = set()
with open(path, 'r') as f:
for line in f:
word = line.lower().strip()
result.add(word)
return result
def find_top(paths, n):
gen = ((len(x), x) for x in paths)
return heapq.nlargest(n, gen)
if __name__ == '__main__':
words = load('TWL06.txt')
gen = search(words, 'b', [])
top = find_top(gen, 10)
for path in top:
print path
もちろん、答えには多くの結びつきがあります。これにより、最終単語の長さで測定された上位 N 個の結果が出力されます。
TWL06 Scrabble ディクショナリを使用した、開始文字「a」の出力。
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampedes', 'stampeders'))
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampeder', 'stampeders'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangles', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangler', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangles', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangers', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'strangers', 'estrangers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranges', 'estranges', 'estrangers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranger', 'strangler', 'stranglers'))
(10, ('a', 'ta', 'tan', 'tang', 'stang', 'strang', 'strange', 'stranger', 'strangers', 'stranglers'))
そして、これが各開始文字の結果です。もちろん、単一の開始文字が辞書にある必要はないという例外があります。それを使って形成できる2文字の単語。
(10, ('a', 'ta', 'tap', 'tape', 'taped', 'tamped', 'stamped', 'stampede', 'stampedes', 'stampeders'))
(9, ('b', 'bo', 'bos', 'bods', 'bodes', 'bodies', 'boodies', 'bloodies', 'bloodiest'))
(1, ('c',))
(10, ('d', 'od', 'cod', 'coed', 'coped', 'comped', 'compted', 'competed', 'completed', 'complected'))
(10, ('e', 're', 'rue', 'ruse', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(9, ('f', 'fe', 'foe', 'fore', 'forge', 'forges', 'forgoes', 'forgoers', 'foregoers'))
(10, ('g', 'ag', 'tag', 'tang', 'stang', 'strang', 'strange', 'strangle', 'strangles', 'stranglers'))
(9, ('h', 'sh', 'she', 'shes', 'ashes', 'sashes', 'slashes', 'splashes', 'splashers'))
(11, ('i', 'pi', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(7, ('j', 'jo', 'joy', 'joky', 'jokey', 'jockey', 'jockeys'))
(9, ('k', 'ki', 'kin', 'akin', 'takin', 'takins', 'takings', 'talkings', 'stalkings'))
(10, ('l', 'la', 'las', 'lass', 'lassi', 'lassis', 'lassies', 'glassies', 'glassines', 'glassiness'))
(10, ('m', 'ma', 'mas', 'mars', 'maras', 'madras', 'madrasa', 'madrassa', 'madrassas', 'madrassahs'))
(11, ('n', 'in', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(10, ('o', 'os', 'ose', 'rose', 'rouse', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(11, ('p', 'pi', 'pin', 'ping', 'oping', 'coping', 'comping', 'compting', 'competing', 'completing', 'complecting'))
(3, ('q', 'qi', 'qis'))
(10, ('r', 're', 'rue', 'ruse', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(10, ('s', 'us', 'use', 'uses', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(10, ('t', 'ti', 'tin', 'ting', 'sting', 'sating', 'stating', 'estating', 'restating', 'restarting'))
(10, ('u', 'us', 'use', 'uses', 'ruses', 'rouses', 'arouses', 'carouses', 'carousels', 'carrousels'))
(1, ('v',))
(9, ('w', 'we', 'wae', 'wake', 'wakes', 'wackes', 'wackest', 'wackiest', 'whackiest'))
(8, ('x', 'ax', 'max', 'maxi', 'maxim', 'maxima', 'maximal', 'maximals'))
(8, ('y', 'ye', 'tye', 'stye', 'styed', 'stayed', 'strayed', 'estrayed'))
(8, ('z', 'za', 'zoa', 'zona', 'zonae', 'zonate', 'zonated', 'ozonated'))
これを一度やりたい場合は、次のようにします(完全な単語で始める問題に一般化されています):
辞書全体を取得し、ターゲット単語に文字のスーパーセットがないものはすべて破棄します ( length があるとしましょうm)。次に、残りの単語を長さでビンに入れます。長さ の単語ごとにm+1、各文字を削除して、目的の単語が得られるかどうかを確認してください。そうでない場合は、投げます。m+2次に、長さの各単語を長さの有効なセットに対してチェックしm+1、削減できないものを削除します。空のセットが見つかるまで続けます。最後に見つけたものが最も長くなります。
これをすばやく検索したい場合は、接尾辞ツリーのようなデータ構造を構築します。
すべての単語を長さでグループ化します。長さ 2 の単語ごとに、その 2 つの文字をそれぞれ「サブワード」セットに配置し、その単語を各文字の「スーパーワード」セットに追加します。これで、長さ 2 のすべての有効な単語とすべての文字の間にリンクができました。長さ 3 の単語と長さ 2 の有効な単語で同じことを行います。これで、この階層の任意の場所から開始し、幅優先検索を実行して最も深い分岐を見つけることができます。
編集: このソリューションの速度は、言語の構造に大きく依存しますがlog(n)、すべての操作に対してパフォーマンスを備えたセットを使用してすべてを構築することに決めた場合 (つまり、赤黒木などを使用します)、N(m)長い単語があります。m、次に、長さと約時間の単語間のリンクを形成m+1しmます(m+1)*m*N(m+1)*log(N(m))(文字列の比較には、文字列の長さに線形の時間がかかることを考慮してください)。すべてのワード長に対してこれを行う必要があるため、完全なデータ構造を構築するための実行時間は、
(typical word length)^3 * (dictionary length) * log (dictionary length / word length)
(特定の長さの単語への最初のビニングには線形時間がかかるため、無視できます。実行時の実際の式は、単語の長さの分布に依存するため複雑です。単一の単語から実行している場合は、短いサブワードを持つ長い単語の予想数に依存するため、さらに複雑になります。)
これを繰り返し行う必要がある場合 (または 26 文字すべての答えが必要な場合) は、逆の手順で行います。
次に、特定のプレフィックスのチェーンを取得するには、そのプレフィックスから始めて、それとその拡張子を辞書で繰り返し調べます。
サンプルの Python コードは次のとおりです。
words = [x.strip().lower() for x in open('/usr/share/dict/words')]
words.sort(key=lambda x:len(x), reverse=True)
word_map = {} # Maps words to (extension, max_len) tuples
for word in words:
if word in word_map:
max_len = word_map[word][1]
else:
max_len = len(word)
for i in range(len(word)):
new_word = word[:i] + word[i+1:]
if new_word not in word_map or word_map[new_word][2] < max_len:
word_map[new_word] = (word, max_len)
# Get a chain for each letter
for term in "abcdefghijklmnopqrstuvwxyz":
chain = [term]
while term in word_map:
term = word_map[term][0]
chain.append(term)
print chain
そして、アルファベットの各文字の出力:
['a', 'ah', 'bah', 'bach', 'brach', 'branch', 'branchi', 'branchia', 'branchiae', 'branchiate', 'abranchiate']
['b', 'ba', 'bac', 'bach', 'brach', 'branch', 'branchi', 'branchia', 'branchiae', 'branchiate', 'abranchiate']
['c', 'ca', 'cap', 'camp', 'campo', 'campho', 'camphor', 'camphory', 'camphoryl', 'camphoroyl']
['d', 'ad', 'cad', 'card', 'carid', 'carida', 'caridea', 'acaridea', 'acaridean']
['e', 'er', 'ser', 'sere', 'secre', 'secret', 'secreto', 'secretor', 'secretory', 'asecretory']
['f', 'fo', 'fot', 'frot', 'front', 'afront', 'affront', 'affronte', 'affronted']
['g', 'og', 'log', 'logy', 'ology', 'oology', 'noology', 'nosology', 'nostology', 'gnostology']
['h', 'ah', 'bah', 'bach', 'brach', 'branch', 'branchi', 'branchia', 'branchiae', 'branchiate', 'abranchiate']
['i', 'ai', 'lai', 'lain', 'latin', 'lation', 'elation', 'delation', 'dealation', 'dealbation']
['j', 'ju', 'jug', 'juga', 'jugal', 'jugale']
['k', 'ak', 'sak', 'sake', 'stake', 'strake', 'straked', 'streaked']
['l', 'la', 'lai', 'lain', 'latin', 'lation', 'elation', 'delation', 'dealation', 'dealbation']
['m', 'am', 'cam', 'camp', 'campo', 'campho', 'camphor', 'camphory', 'camphoryl', 'camphoroyl']
['n', 'an', 'lan', 'lain', 'latin', 'lation', 'elation', 'delation', 'dealation', 'dealbation']
['o', 'lo', 'loy', 'logy', 'ology', 'oology', 'noology', 'nosology', 'nostology', 'gnostology']
['p', 'pi', 'pig', 'prig', 'sprig', 'spring', 'springy', 'springly', 'sparingly', 'sparringly']
['q']
['r', 'ra', 'rah', 'rach', 'brach', 'branch', 'branchi', 'branchia', 'branchiae', 'branchiate', 'abranchiate']
['s', 'si', 'sig', 'spig', 'sprig', 'spring', 'springy', 'springly', 'sparingly', 'sparringly']
['t', 'ut', 'gut', 'gutt', 'gutte', 'guttle', 'guttule', 'guttulae', 'guttulate', 'eguttulate']
['u', 'ut', 'gut', 'gutt', 'gutte', 'guttle', 'guttule', 'guttulae', 'guttulate', 'eguttulate']
['v', 'vu', 'vum', 'ovum']
['w', 'ow', 'low', 'alow', 'allow', 'hallow', 'shallow', 'shallowy', 'shallowly']
['x', 'ox', 'cox', 'coxa', 'coxal', 'coaxal', 'coaxial', 'conaxial']
['y', 'ly', 'loy', 'logy', 'ology', 'oology', 'noology', 'nosology', 'nostology', 'gnostology']
['z', 'za', 'zar', 'izar', 'izard', 'izzard', 'gizzard']
編集:ブランチが最後にマージする程度を考えると、これを示すグラフを描くのは興味深いと思いました:
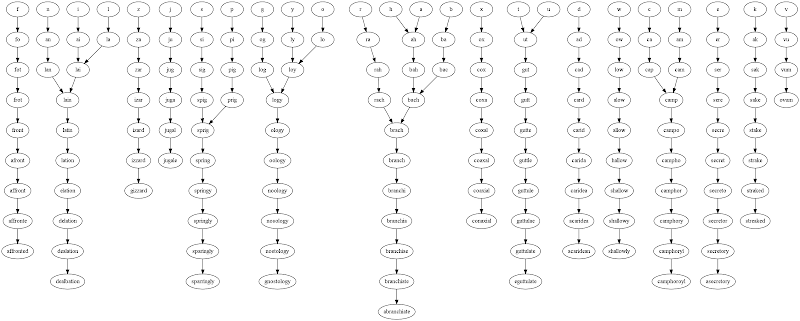
この課題の興味深い拡張: いくつかの文字には、同じ長さの最後の単語がいくつかある可能性があります。最終ノードの数を最小化するチェーンのセットはどれですか (たとえば、最も多くの文字をマージします)?
{kind=link}