正規表現がより長い代替に一致するというあなたの仮定は正しくありません。
少し時間があれば、正規表現がどのように機能するかを見てみましょう...
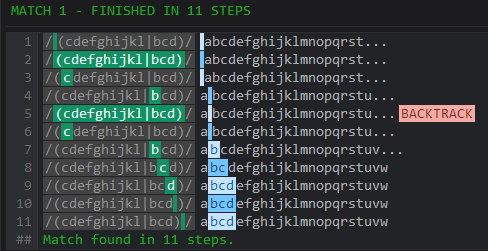
簡単な復習: 正規表現のしくみ: ステート マシンは常に左から右に読み取り、必要に応じてバックトラックします。
2 つのポインターがあり、1 つはパターン上にあります。
(cdefghijkl|bcd)
あなたの文字列のもう一方:
abcdefghijklmnopqrstuvw
String 上のポインタは左から移動します。戻ることができるとすぐに、次のようになります。

(出典:gyazo.com)
理解するために、これをより「連続した」シーケンスに変えてみましょう。

(出典:gyazo.com)
あなたのfoobar例は別のトピックです。この投稿で述べたように:
正規表現の仕組み: ステート マシンは常に左から右に読み取ります。,|,, == ,、常に最初の代替にのみ一致するためです。
いいですね、Unihedron ですが、最初の交替に強制するにはどうすればよいですか
見て!*
^(?:.*?\Kcdefghijkl|.*?\Kbcd)
ここにregex demoがあります。
この正規表現は、最初に文字列全体を最初の代替と一致させようとします。完全に失敗した場合にのみ、2 番目の代替との一致を試みます。\Kここでは、constructの背後にあるコンテンツとの一致を維持するために使用されます。\K
*: \KRuby では 2.0.0 からサポートされていました。
続きを読む:
ああ、退屈だったので、正規表現を最適化しました。
^(?:(?:(?!cdefghijkl)c?[^c]*)++\Kcdefghijkl|(?:(?!bcd)b?[^b]*)++\Kbcd)
ここでデモを見ることができます。
{kind=link}
{kind=link}