このスレッドに関する私の回答のコメントの結果として、私は+=オペレーターとの速度の違いが何であるかを知りたいと思いました''.join()
では、2つの速度の比較は何ですか?
このスレッドに関する私の回答のコメントの結果として、私は+=オペレーターとの速度の違いが何であるかを知りたいと思いました''.join()
では、2つの速度の比較は何ですか?
From:効率的な文字列連結
方法1:
def method1():
out_str = ''
for num in xrange(loop_count):
out_str += 'num'
return out_str
方法4:
def method4():
str_list = []
for num in xrange(loop_count):
str_list.append('num')
return ''.join(str_list)
今では、それらが厳密に代表的なものではなく、4番目の方法が各項目を繰り返して結合する前にリストに追加されることに気付きましたが、これは公正な指標です。
文字列結合は、連結よりも大幅に高速です。
なんで?文字列は不変であり、その場で変更することはできません。1つを変更するには、新しい表現を作成する必要があります(2つの連結)。
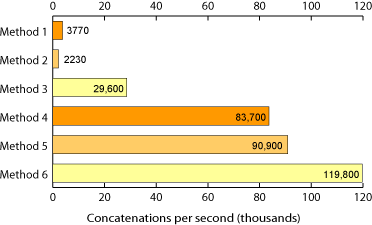
私の元のコードは間違っていました。+連結は通常より高速であるようです(特に新しいハードウェア上の新しいバージョンのPythonでは)
時間は次のとおりです。
Iterations: 1,000,000
Windows 7、Corei7上のPython3.3
String of len: 1 took: 0.5710 0.2880 seconds
String of len: 4 took: 0.9480 0.5830 seconds
String of len: 6 took: 1.2770 0.8130 seconds
String of len: 12 took: 2.0610 1.5930 seconds
String of len: 80 took: 10.5140 37.8590 seconds
String of len: 222 took: 27.3400 134.7440 seconds
String of len: 443 took: 52.9640 170.6440 seconds
Windows 7、Corei7上のPython2.7
String of len: 1 took: 0.7190 0.4960 seconds
String of len: 4 took: 1.0660 0.6920 seconds
String of len: 6 took: 1.3300 0.8560 seconds
String of len: 12 took: 1.9980 1.5330 seconds
String of len: 80 took: 9.0520 25.7190 seconds
String of len: 222 took: 23.1620 71.3620 seconds
String of len: 443 took: 44.3620 117.1510 seconds
Linux Mint、Python 2.7、一部の低速プロセッサ
String of len: 1 took: 1.8840 1.2990 seconds
String of len: 4 took: 2.8394 1.9663 seconds
String of len: 6 took: 3.5177 2.4162 seconds
String of len: 12 took: 5.5456 4.1695 seconds
String of len: 80 took: 27.8813 19.2180 seconds
String of len: 222 took: 69.5679 55.7790 seconds
String of len: 443 took: 135.6101 153.8212 seconds
そしてここにコードがあります:
from __future__ import print_function
import time
def strcat(string):
newstr = ''
for char in string:
newstr += char
return newstr
def listcat(string):
chars = []
for char in string:
chars.append(char)
return ''.join(chars)
def test(fn, times, *args):
start = time.time()
for x in range(times):
fn(*args)
return "{:>10.4f}".format(time.time() - start)
def testall():
strings = ['a', 'long', 'longer', 'a bit longer',
'''adjkrsn widn fskejwoskemwkoskdfisdfasdfjiz oijewf sdkjjka dsf sdk siasjk dfwijs''',
'''this is a really long string that's so long
it had to be triple quoted and contains lots of
superflous characters for kicks and gigles
@!#(*_#)(*$(*!#@&)(*E\xc4\x32\xff\x92\x23\xDF\xDFk^%#$!)%#^(*#''',
'''I needed another long string but this one won't have any new lines or crazy characters in it, I'm just going to type normal characters that I would usually write blah blah blah blah this is some more text hey cool what's crazy is that it looks that the str += is really close to the O(n^2) worst case performance, but it looks more like the other method increases in a perhaps linear scale? I don't know but I think this is enough text I hope.''']
for string in strings:
print("String of len:", len(string), "took:", test(listcat, 1000000, string), test(strcat, 1000000, string), "seconds")
testall()
既存の回答は非常によく書かれており、調査されていますが、Python 3.6時代の別の回答があります。これは、リテラル文字列補間(AKA、f-strings)があるためです。
>>> import timeit
>>> timeit.timeit('f\'{"a"}{"b"}{"c"}\'', number=1000000)
0.14618930302094668
>>> timeit.timeit('"".join(["a", "b", "c"])', number=1000000)
0.23334730707574636
>>> timeit.timeit('a = "a"; a += "b"; a += "c"', number=1000000)
0.14985873899422586
2.3GHzのIntelCorei7を搭載した2012RetinaMacBookProでCPython3.6.5を使用してテストを実行しました。
これは決して正式なベンチマークではありませんが、f-stringsを使用すると、+=連結を使用する場合とほぼ同じようにパフォーマンスが向上するようです。もちろん、改善された指標や提案は大歓迎です。
私は最後の答えを書き直しました、jouは私がテストした方法についてあなたの意見を共有できますか?
import time
start1 = time.clock()
for x in range (10000000):
dog1 = ' and '.join(['spam', 'eggs', 'spam', 'spam', 'eggs', 'spam','spam', 'eggs', 'spam', 'spam', 'eggs', 'spam'])
end1 = time.clock()
print("Time to run Joiner = ", end1 - start1, "seconds")
start2 = time.clock()
for x in range (10000000):
dog2 = 'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'+' and '+'spam'+' and '+'eggs'+' and '+'spam'
end2 = time.clock()
print("Time to run + = ", end2 - start2, "seconds")
注:この例はPython 3.5で記述されており、range()は以前のxrange()のように機能します
私が得た出力:
Time to run Joiner = 27.086106206103153 seconds
Time to run + = 69.79100515996426 seconds
個人的には、「Plusserway」よりも「.join([])」の方がクリーンで読みやすいので好きです。
よく予想される場合、合計n文字のk文字列のリストの場合、結合の時間計算量はO(nlogk)であり、従来の連結の時間計算量はO(nk)である必要があります。
これは、k個のソートされたリストをマージする場合と同じ相対コストになります(効率的な方法はO(nlkg)ですが、連結に似た単純な方法はO(nk)です)。
これは愚かなプログラムがテストするように設計されているものです:)
プラスを使用
import time
if __name__ == '__main__':
start = time.clock()
for x in range (1, 10000000):
dog = "a" + "b"
end = time.clock()
print "Time to run Plusser = ", end - start, "seconds"
出力:
Time to run Plusser = 1.16350010965 seconds
今すぐ参加して...
import time
if __name__ == '__main__':
start = time.clock()
for x in range (1, 10000000):
dog = "a".join("b")
end = time.clock()
print "Time to run Joiner = ", end - start, "seconds"
出力:
Time to run Joiner = 21.3877386651 seconds
したがって、Windows上のPython 2.6では、+はjoinよりも約18倍高速です:)