次の言語を特徴とする正規表現を定義する方法は?
L = {w ∈ {a, b}* | w の b は偶数です}
関連するオートマトンを作成しようとしました:

それから、アルゴリズムを適用してDFAから正規表現を取得しようとしたところ、次の式が得られましa*ba*bた。
これが正しい答えでしょうか?
次の言語を特徴とする正規表現を定義する方法は?
L = {w ∈ {a, b}* | w の b は偶数です}
関連するオートマトンを作成しようとしました:
それから、アルゴリズムを適用してDFAから正規表現を取得しようとしたところ、次の式が得られましa*ba*bた。
これが正しい答えでしょうか?
近いですが、パターンa*の最後に a が必要です。また、アンカーが必要で、文字列の開始^と$終了を指定する必要があります。次に、すべての正規表現をキャプチャ グループ内に配置し、*偶数の場合に一致させるために使用できます。 b、および のa*ゼロ数b:
^((a*ba*ba*)*|a*)$
注:|は論理 OR であり、正規表現エンジンを(a*ba*ba*)*orに一致させますa*。
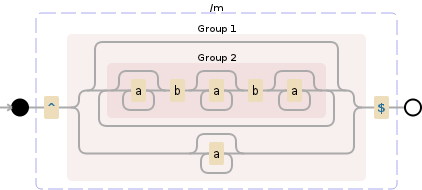
よりエレガントにすることもできますが、最初に正規表現にあまり慣れていないため、前のパターンを提案しました。
たとえば、次のように動作します。
^(((a*b){2})*)a*$