単語のグループを除外しようとしていますが、別の単語のグループを qregexp 式に含めようとしていますが、現在これを理解するのに問題があります。
ここに私が試したことのいくつかがあります(この例にはすべての単語が含まれています):
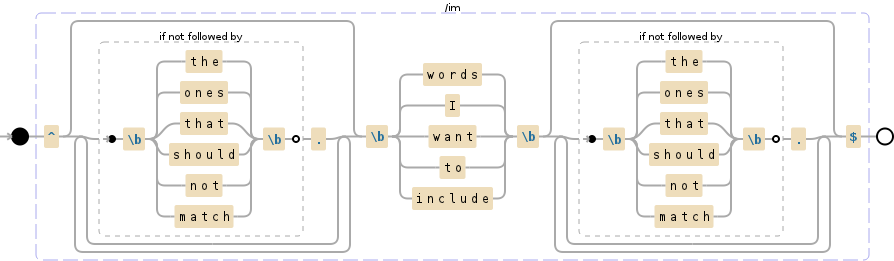
(words|I|want|to|include)(?!the|ones|that|should|not|match)
だから私はこれを試しました(何も返されませんでした):
^(words|I|want|to|include)(?:(?!the|ones|that|should|not|match).)*$
何か不足していますか?
編集: このような珍しい正規表現 (包含/除外) が必要な理由は、一連の記事を検索して、含まれている単語が含まれているが、除外されている単語も含まれている記事をフィルタリングしたいからです。
たとえば、記事 A が次の場合:
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
記事Bは次のとおりです。
Vivamus fermentum semper porta.
次に、を含む正規表現はlorem記事 A をフィルター処理しますが、B はフィルター処理ipsumしません。
正規表現を使用して、必要な単語を含む記事を除外し、最初のセットから不要な記事を除外する 2 番目の正規表現を実行することを検討しましたが、残念ながら、使用しているソフトウェアではこれを行うことができません。実行できる正規表現は 1 つだけです。