ラスタライズされた PDF の CText フィールドを PNG 形式に変換し、OpenCV で画像を分析して検出しようとしています。
これまでのところ、次のコードを使用して、比較的正確な一連のコーナーを作成できました。
image = cv2.imread(img_filename)
# add 10px border padding (white)
image = cv2.copyMakeBorder(image, 10, 10, 10, 10, cv2.BORDER_CONSTANT, value=[255, 255, 255])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
corners = cv2.cornerHarris(gray, 2, 3, 0.1)
cond = corners>0.0001*corners.max()
image[cond] = [0,0,255]
cv2.imshow('dst', image)
cv2.waitKey(0)
ここに私の入力があります:

出力は次のとおりです。
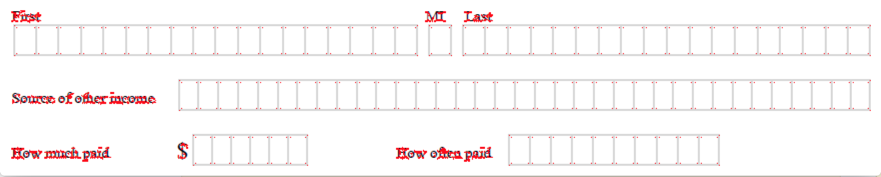
このポイントのセットから、どのポイントが長方形の一部であるかを計算できるようにしたいと考えています。これには、各コーナー ポイントに対して、他の 3 つのコーナー ポイントが存在することを確認する必要があります。
- 同じ行 (ほぼ) にあるが、列が異なるポイント
- 同じ列 (ほぼ) であるが、行が異なるポイント
- 上の(1)の列と上の(2)の行を持つポイント
目標は、それらのコーナーポイントが長方形自体に属していない限り、内部に [有意な] 量のコーナーポイントを含まない長方形のセットを生成することです(たとえば、各内側の長方形の境界長方形の場合)。 )
OpenCVでこれを行う最も効率的な方法は何ですか?