私は現在、Tensorflow を学習しようとしていますが、いくつかのコーパスのデータセットを作成する必要があるところまで来ています。LDC の注釈付き Gigaword 英語コーパスに投じるお金がないので、独自のスクレーパーを作成することを考えています。オンラインからいくつかの記事を入手しましたが、ここで LDC Gigaword サンプルと同様の方法でフォーマットしたいと思います: https://catalog.ldc.upenn.edu/desc/addenda/LDC2012T21.jpg
{kind=link}
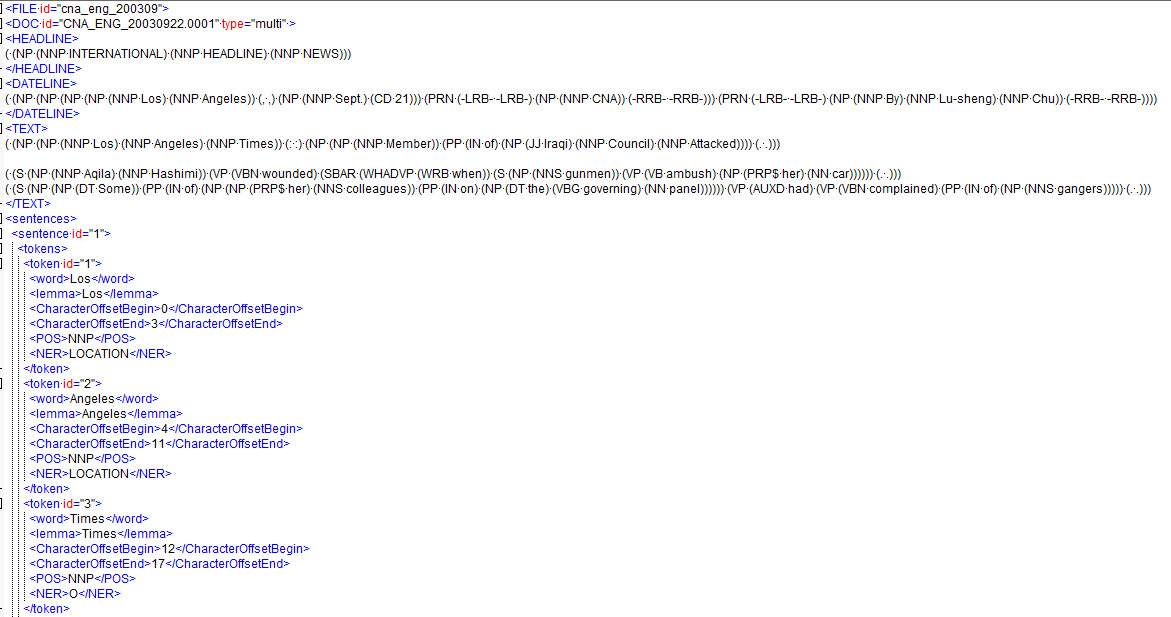
Parsey Mcparseface モデルを使用して、入力に POS タグを付け、複数の xml ファイルを出力しようとしています。私は現在、pythonを使用してconll2tree.pyファイルとdemo.shファイルを変更して、単一のファイルから入力を読み取れるようにすることで、必要な出力に近づきました。使用したコマンドラインは、この投稿の下部に示されています。
私が理解しようとしているのは、モデルがディレクトリ内のすべてのファイルを処理する方法です。私の現在のスクレーパーは JavaScript で書かれており、タイトル、本文、画像などの json オブジェクトを含む個別の .json ファイルを出力します。文の境界検出を使用して各文をコンマで区切りましたが、解析への入力が必要になるようです各文が異なる行にある入力になります。これを Python スクリプトで変更しますが、各ファイルを反復処理し、コンテンツを読み込んで処理し、次のファイルに移動できるように、以下のパラメーターを構成する方法についてはまだわかりません。入力パラメータにワイルドカードを設定する方法はありますか? または、Python スクリプトでコマンドライン経由で各ファイルを個別に送信する必要がありますか? パーシーモデルまたはSyntexNetがそれらをバッチで処理できる方法があるかどうかを推測します。
私が持っていたもう1つの質問は、上の画像の「見出し」に示されているような形式をParsey Mcparsefaceに出力させる方法があるかどうかです。
(.(NP.(NNP.INTERNATIONAL).(NNP.HEADLINE).(NNP.NEWS)))
そうでない場合、この形式は何と呼ばれているので、コードを介して自分でこれを行う方法を詳しく調べることができますか? 私をうんざりさせている部分は、NPのプレフィックス番号です(名詞句を想定)。
文のトークンを介して示されている画像のような形式に POS タグを抽出することができましたが、Tensorflow を深く理解するにつれて、それらが表示されている形式にするのが良いと思います。単語同士の関係をより多く示すため、headline タグと textfield タグも同様です。
PARSER_EVAL=bazel-bin/syntaxnet/parser_eval
MODEL_DIR=syntaxnet/models/parsey_mcparseface
[[ "$1" == "--conll" ]] && INPUT_FORMAT=stdin-conll || INPUT_FORMAT=stdin
#--input=testin \
#--input=$INPUT_FORMAT \
$PARSER_EVAL \
--input=testin \
--output=stdout-conll \
--hidden_layer_sizes=64 \
--arg_prefix=brain_tagger \
--graph_builder=structured \
--task_context=$MODEL_DIR/context.pbtxt \
--model_path=$MODEL_DIR/tagger-params \
--slim_model \
--batch_size=1024 \
--alsologtostderr \
| \
$PARSER_EVAL \
--input=stdin-conll \
--output=testout \
--hidden_layer_sizes=512,512 \
--arg_prefix=brain_parser \
--graph_builder=structured \
--task_context=$MODEL_DIR/context.pbtxt \
--model_path=$MODEL_DIR/parser-params \
--slim_model \
--batch_size=1024 \
--alsologtostderr \
| \
bazel-bin/syntaxnet/danspos \
--task_context=$MODEL_DIR/context.pbtxt \
--alsologtostderr
また、次のエントリを content.pbtxt ファイルに追加しました。
input {
name: 'testin'
record_format: 'english-text'
Part {
file_pattern: './testinp.txt'
}
}
input {
name: 'testout'
record_format: 'conll-sentence'
Part {
file_pattern: './testoutput.txt'
}
}