これが、私がこの質問をしている理由です。 昨年、特定のタイプのモデル (ベイジアン ネットワークで記述) の事後確率を計算する C++ コードをいくつか作成しました。このモデルはうまく機能し、他の人が私のソフトウェアを使い始めました。今、私は自分のモデルを改善したいと考えています。私はすでに新しいモデル用にわずかに異なる推論アルゴリズムをコーディングしているので、ランタイムはそれほど重要ではなく、Python を使用するとよりエレガントで扱いやすいコードを作成できる可能性があるため、Python を使用することにしました。
通常、このような状況では、Python で既存のベイジアン ネットワーク パッケージを検索しますが、使用している推論アルゴリズムは独自のものであり、Python の優れた設計についてさらに学ぶ絶好の機会になると考えました。
ネットワーク グラフ用の優れた Python モジュール (networkx) を既に見つけました。これにより、各ノードと各エッジに辞書をアタッチできます。基本的に、これにより、ノードとエッジのプロパティを指定できます。
特定のネットワークとその観測データについて、モデル内の割り当てられていない変数の可能性を計算する関数を作成する必要があります。
たとえば、従来の「アジア」ネットワーク ( http://www.bayesserver.com/Resources/Images/AsiaNetwork.png ) では、「XRay Result」と「Dyspnea」の状態がわかっているため、関数を記述する必要があります。他の変数が特定の値を持つ可能性を計算します (モデルに従って)。
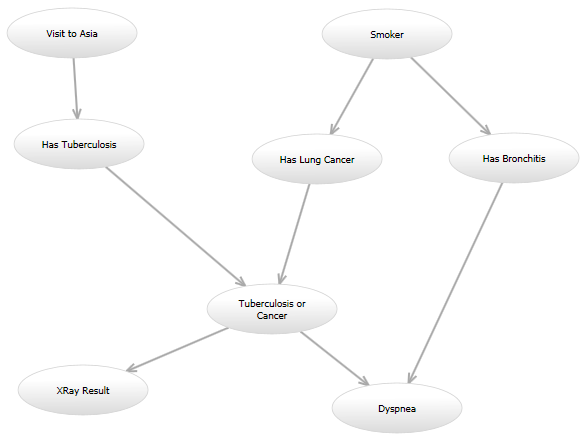{kind=link}
これが私のプログラミングに関する質問です。 いくつかのモデルを試してみるつもりですが、将来的には別のモデルを試してみたいと思うかもしれません。たとえば、1 つのモデルがアジア ネットワークとまったく同じように見える場合があります。別のモデルでは、「Visit to Asia」から「Has Lung Cancer」に有向エッジが追加される場合があります。別のモデルは元の有向グラフを使用する場合がありますが、「結核または癌」ノードと「気管支炎あり」ノードが与えられた場合、「呼吸困難」ノードの確率モデルは異なる場合があります。これらのモデルはすべて、異なる方法で尤度を計算します。
すべてのモデルにはかなりの重複があります。たとえば、「Or」ノードに入る複数のエッジは、すべての入力が「0」の場合は常に「0」になり、それ以外の場合は「1」になります。ただし、モデルによっては、ある範囲の整数値を取るノードを持つものもあれば、ブール型のものもあります。
過去に、私はこのようなことをプログラムする方法に苦労しました。うそをつくつもりはありません。かなりの量のコードをコピーして貼り付けており、1 つのメソッドの変更を複数のファイルに反映する必要がある場合がありました。今回は、これを正しい方法で行うために時間を費やしたいと思っています。
いくつかのオプション:
- 私はすでにこれを正しい方法で行っていました。最初にコーディングし、後で質問します。コードをコピーして貼り付け、モデルごとに 1 つのクラスを作成する方が高速です。世界は暗く無秩序な場所です...
- 各モデルは独自のクラスですが、一般的な BayesianNetwork モデルのサブクラスでもあります。この一般的なモデルは、オーバーライドされるいくつかの関数を使用します。Stroustrup は誇りに思うでしょう。
- 異なる尤度を計算する同じクラスにいくつかの関数を作成します。
- 一般的な BayesianNetwork ライブラリをコーディングし、このライブラリによって読み取られる特定のグラフとして推論の問題を実装します。ノードとエッジには、"Boolean" や "OrFunction" などのプロパティを指定する必要があります。これらは、親ノードの既知の状態を考慮して、さまざまな結果の確率を計算するために使用できます。これらのプロパティ文字列 ("OrFunction" など) を使用して、適切な関数を検索して呼び出すこともできます。おそらく数年後には、1988 年版の Mathematica に似たものを作ることになるでしょう!
どうもありがとうございました。
更新: ここではオブジェクト指向のアイデアが大いに役立ちます (各ノードには、特定のノード サブタイプの先行ノードの指定されたセットがあり、各ノードには、先行ノードの状態などを考慮して、さまざまな結果状態の可能性を計算する尤度関数があります。 )。おっと!