変化しない配列の値を繰り返し検索したい。
これまでのところ、私はこのようにしてきました: 値をハッシュに入れ (つまり、配列と本質的に同じ内容のハッシュを持っています)、 を使用してハッシュを検索しexistsます。
2 つの異なる変数 (配列とハッシュ) が同じものを格納するのは好きではありません。ただし、ハッシュは検索がはるかに高速です。
~~Perl 5.10 に (スマートマッチ) 演算子があることがわかりました。配列内のスカラーを検索するときの効率はどれくらいですか?
変化しない配列の値を繰り返し検索したい。
これまでのところ、私はこのようにしてきました: 値をハッシュに入れ (つまり、配列と本質的に同じ内容のハッシュを持っています)、 を使用してハッシュを検索しexistsます。
2 つの異なる変数 (配列とハッシュ) が同じものを格納するのは好きではありません。ただし、ハッシュは検索がはるかに高速です。
~~Perl 5.10 に (スマートマッチ) 演算子があることがわかりました。配列内のスカラーを検索するときの効率はどれくらいですか?
配列内の単一のスカラーを検索する場合は、 List::Utilのfirstサブルーチンを使用できます。答えがわかるとすぐに停止します。既に hash を持っている場合、これがハッシュ検索よりも高速になるとは思いませんが、ハッシュを作成してメモリに保持することを検討する場合は、既に持っている配列を検索する方が便利かもしれません。
スマートマッチ演算子の賢さについては、それがどれほど賢いかを知りたい場合は、テストしてください。:)
調べたいケースが少なくとも 3 つあります。最悪のケースは、検索したいすべての要素が最後にあるということです。最良のケースは、検索するすべての要素が先頭にあることです。可能性の高いケースは、見つけたい要素が平均して真ん中にあるということです。
さて、このベンチマークを開始する前に、スマート マッチが短絡する可能性がある場合 (そして可能です; perlsynに文書化されています)、最良のケースの時間は配列のサイズに関係なく同じままであり、他の時間はますます悪化することを期待しています。 . 短絡できず、毎回アレイ全体をスキャンする必要がある場合、すべてのケースで同じ量の作業が必要になるため、時間に違いはありません。
ベンチマークは次のとおりです。
#!perl
use 5.12.2;
use strict;
use warnings;
use Benchmark qw(cmpthese);
my @hits = qw(A B C);
my @base = qw(one two three four five six) x ( $ARGV[0] || 1 );
my @at_end = ( @base, @hits );
my @at_beginning = ( @hits, @base );
my @in_middle = @base;
splice @in_middle, int( @in_middle / 2 ), 0, @hits;
my @random = @base;
foreach my $item ( @hits ) {
my $index = int rand @random;
splice @random, $index, 0, $item;
}
sub count {
my( $hits, $candidates ) = @_;
my $count;
foreach ( @$hits ) { when( $candidates ) { $count++ } }
$count;
}
cmpthese(-5, {
hits_beginning => sub { my $count = count( \@hits, \@at_beginning ) },
hits_end => sub { my $count = count( \@hits, \@at_end ) },
hits_middle => sub { my $count = count( \@hits, \@in_middle ) },
hits_random => sub { my $count = count( \@hits, \@random ) },
control => sub { my $count = count( [], [] ) },
}
);
各種パーツの出来上がりはこんな感じ。これは両方の軸の対数プロットであるため、プランジ ラインの傾きは見た目ほど近くないことに注意してください。
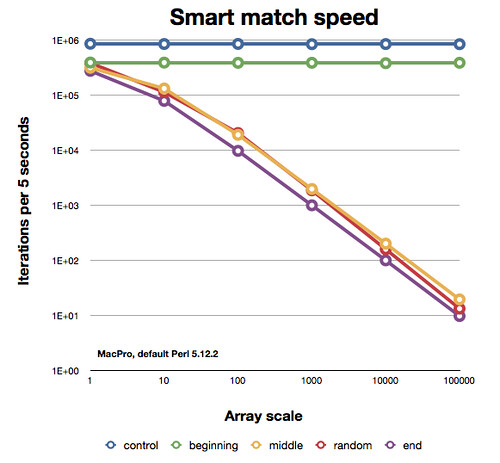
したがって、スマート マッチ演算子は少し賢いように見えますが、それでも配列全体をスキャンする必要がある可能性があるため、実際には役に立ちません。要素がどこにあるのか、事前にはわからないでしょう。いくらかのメモリをあきらめる必要があるとしても、ハッシュは最良のケースのスマートマッチと同じように機能すると思います。
さて、スマート マッチはスマート 2 倍であることは素晴らしいことですが、本当の問題は「これを使用する必要があるかどうか」です。別の方法はハッシュ ルックアップですが、そのケースを考慮していないことに悩まされています。
他のベンチマークと同様に、実際にテストする前に、結果がどうなるかを考えることから始めます。ハッシュが既にある場合、値の検索は非常に高速になると思います。そのケースは問題ありません。ハッシュがまだない場合にもっと興味があります。どのくらいの速さでハッシュを作成し、キーを検索できますか? あまりうまく機能しないと思いますが、最悪の場合のスマートマッチよりも優れていますか?
ただし、ベンチマークを確認する前に、数字を見るだけでは、どの手法を使用すべきかについて十分な情報が得られることはほとんどないことを覚えておいてください。問題のコンテキストによって最適な手法が選択されますが、最速でコンテキストのないマイクロベンチマークではありません。異なる手法を選択するいくつかのケースを考えてみましょう:
これらを念頭に置いて、以前のプログラムに追加します。
my %old_hash = map {$_,1} @in_middle;
cmpthese(-5, {
...,
new_hash => sub {
my %h = map {$_,1} @in_middle;
my $count = 0;
foreach ( @hits ) { $count++ if exists $h{$_} }
$count;
},
old_hash => sub {
my $count = 0;
foreach ( @hits ) { $count++ if exists $old_hash{$_} }
$count;
},
control_hash => sub {
my $count = 0;
foreach ( @hits ) { $count++ }
$count;
},
}
);
これがプロットです。色は少し見分けがつきにくいです。一番下の行は、検索するたびにハッシュを作成する必要がある場合です。それはかなり悪いです。一番上の 2 行 (緑) は、ハッシュ (実際にはハッシュはありません) と既存のハッシュ ルックアップのコントロールです。これはログ/ログ プロットです。これら 2 つのケースは、スマート マッチ コントロール (サブルーチンを呼び出すだけ) よりも高速です。

他にも注意すべき点がいくつかあります。「ランダム」の場合の行は少し異なります。各ベンチマーク (つまり、配列スケールの実行ごとに 1 回) はヒット要素を候補配列にランダムに配置するため、これは理解できます。いくつかの実行では少し前に配置し、いくつかは少し後に配置しましたが、@random配列はプログラム全体の実行ごとに 1 回しか作成しないため、少し移動します。つまり、線の隆起は重要ではありません。すべての位置を試して平均した場合、「ランダム」ラインは「中間」ラインと同じであると予想されます。
さて、これらの結果を見ると、最悪の場合のスマート マッチは、最悪の場合のハッシュ ルックアップよりもはるかに高速であると言えます。それは理にかなっている。ハッシュを作成するには、配列のすべての要素にアクセスし、ハッシュも作成する必要がありますが、これは大量のコピーです。スマートマッチではコピーはありません。
これは、私が調べないさらなるケースです。ハッシュがスマートマッチよりも優れているのはいつですか? つまり、ハッシュを作成するオーバーヘッドが、繰り返される検索で十分に広がり、ハッシュがより適切な選択になるのはいつですか?
潜在的な一致の数が少ない場合は高速ですが、ハッシュよりも高速ではありません。ハッシュは、セットのメンバーシップをテストするための適切なツールです。ハッシュ アクセスは O(log n) であり、配列のスマートマッチは依然として O(n) リニア スキャンであるため (grep とは異なり、短絡ではありますが)、許容されるマッチの値が多くなると、スマートマッチは比較的悪化します。
#!perl
use 5.12.0;
use Benchmark qw(cmpthese);
my @hits = qw(one two three);
my @candidates = qw(one two three four five six); # 50% hit rate
my %hash;
@hash{@hits} = ();
sub count_hits_hash {
my $count = 0;
for (@_) {
$count++ if exists $hash{$_};
}
$count;
}
sub count_hits_smartmatch {
my $count = 0;
for (@_) {
$count++ when @hits;
}
$count;
}
say count_hits_hash(@candidates);
say count_hits_smartmatch(@candidates);
cmpthese(-5, {
hash => sub { count_hits_hash((@candidates) x 1000) },
smartmatch => sub { count_hits_smartmatch((@candidates) x 1000) },
}
);
Rate smartmatch hash
smartmatch 404/s -- -65%
hash 1144/s 183% --
「スマート マッチ」の「スマート」は、検索に関するものではありません。コンテキストに基づいて、適切なタイミングで適切なことを行うことです。
配列をループするか、ハッシュにインデックスを付ける方が速いかどうかという問題は、ベンチマークする必要がありますが、一般に、ハッシュにインデックスを付けるよりもすばやく目を通すには、かなり小さな配列でなければなりません。 .