有効なポイントを上げますが、正規化とその意味について完全には明確ではありません。たとえば、
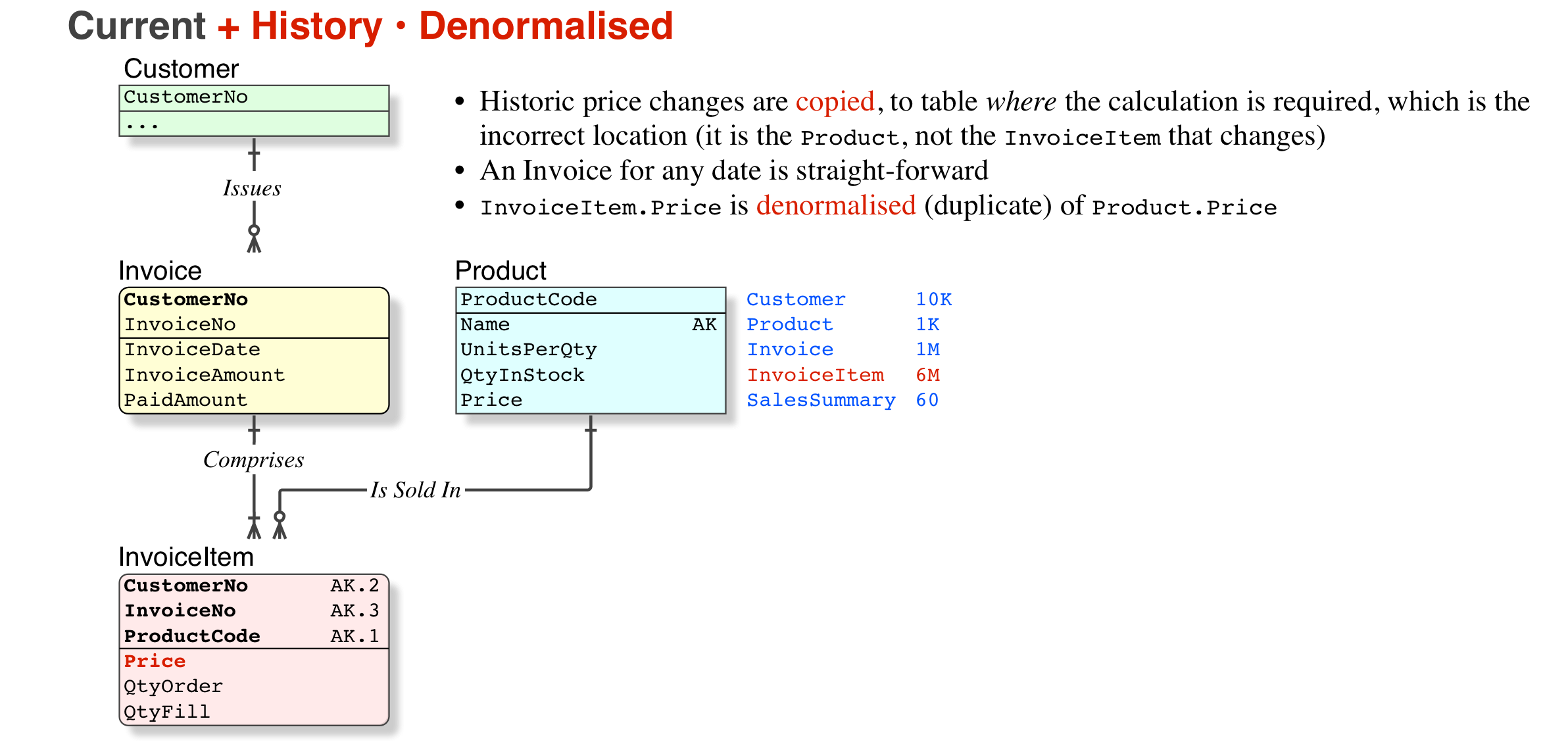
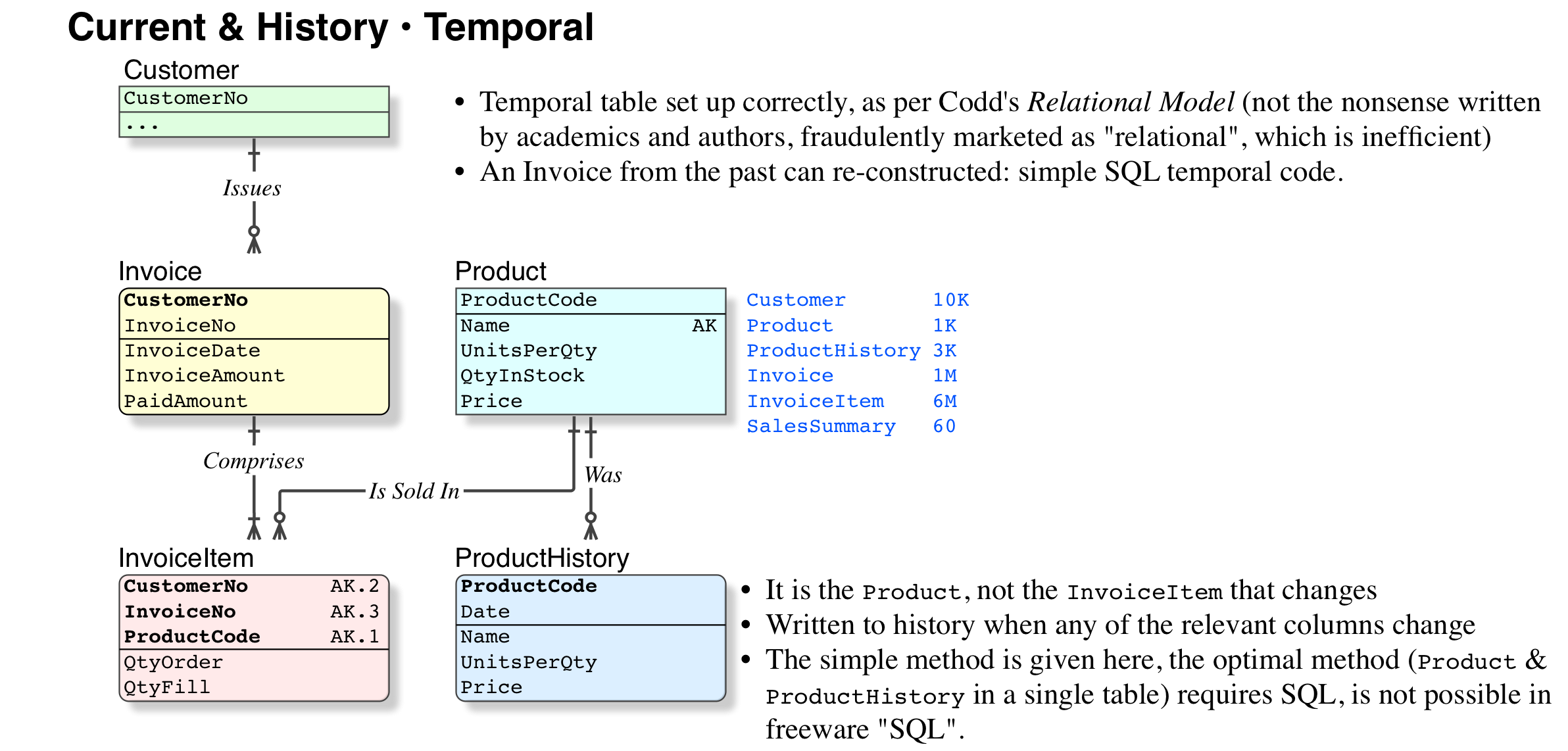
1) 請求書をそのままにしておくとデータが非正規化されるという主張は、完全に完全に間違っています。価格を例に取りましょう。価格の履歴を保持する必要があるというビジネス要件がある場合、現在の価格のみを保持することは間違っており、要件に違反します。そしてそれは正規化とは何の関係もなく、単純にうまく設計されていません。非正規化とは、モデル (およびその他のアーティファクト) にあいまいさの可能性を導入することです。この場合、問題空間を適切にモデル化していません。
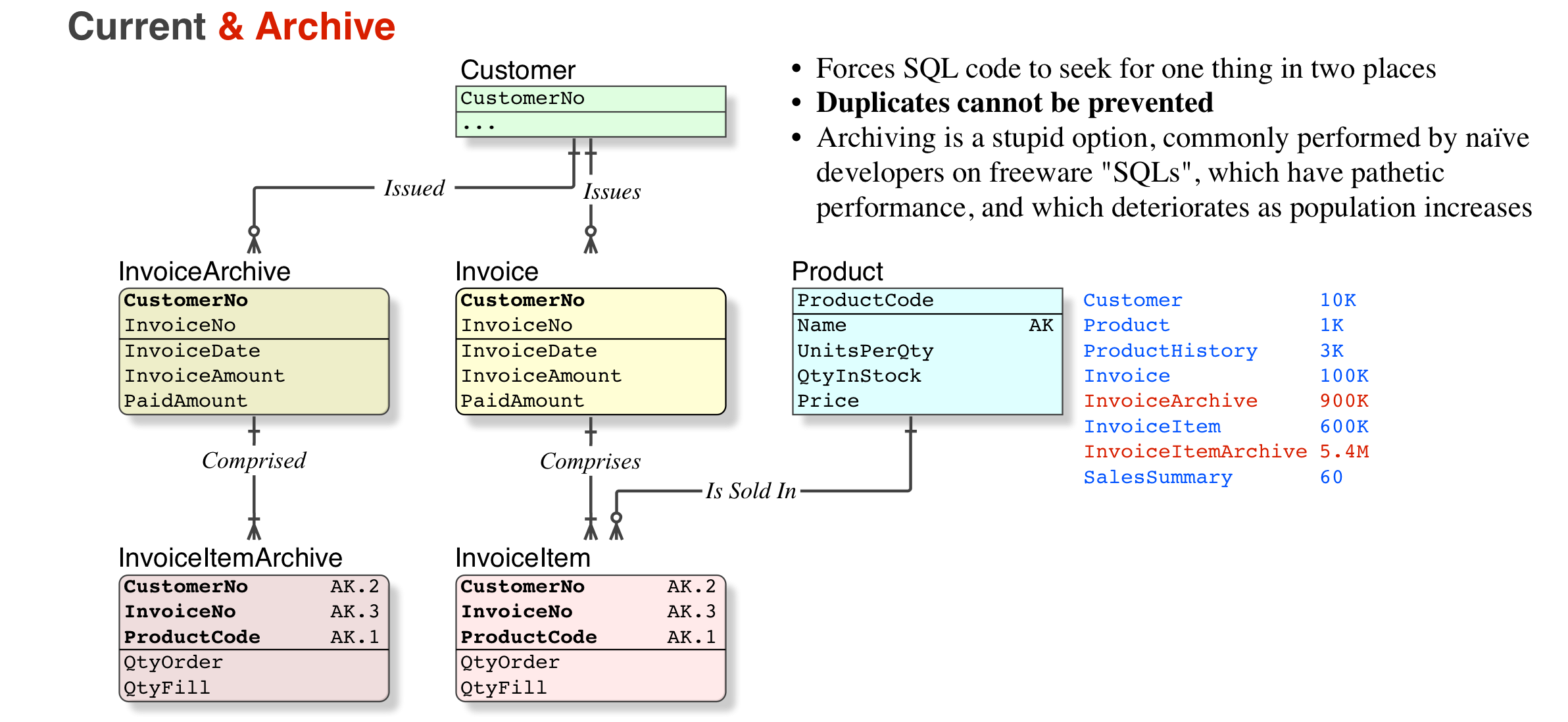
テンポラル データをサポートするためにデータベースをモデル化すること (または、バージョン管理および/またはデータベースの領域をアーカイブ/テンポラルおよびワーキング セットに分離すること) に問題はありません。
セマンティクス (要件の観点から) を検討せずに正規化を検討することはできません。
また、上級開発者が違いがわからない場合は、RDBMS 開発の経験がなかったと思います ;)
2) 2 番目の部分は確かに非正規化です。ただし、正規化を真剣に説くシニア DB アナリストに出くわした場合は、意識的に非正規化を行い、太りすぎの欠乏症に利益をもたらし、異常があなたを噛まないことを確認する限り、非正規化は完全に受け入れられると彼/彼女が言うのを聞くでしょう. また、論理モデルを正規化すること、および物理モデルでは、さまざまな目的 (パフォーマンス、メンテナンスなど) のために理想から逸脱することが許可されていることも伝えられます。私の本では、正規化の主な目的は、隠れた異常がないようにすることです (たとえば、 5NFに関するこの記事を参照してください)。
中間結果のキャッシングは、正規化されたデータベースでも、正規化の最大のエバンジェリストによっても許可されています-アプリケーションレイヤーで(ある種のキャッシュとして)行うことも、データベースレベルで行うことも、データウェアハウスを使用することもできますそのような目的。これらはすべて有効な選択であり、論理モデルの正規化とは関係ありません。
また、あなたの会計士については、彼が主張していることは良いテストではないことを彼に納得させ、ユーザーの介入なしにシステムのテストを自動化し、あなたにシステムにバグがないという確信が高まります。
一方で、実際の行を入力する前または後に請求書に行数を入力するなど、入力が完了していることを確認するために、ユーザーが重複した情報を入力する必要があるシステムを知っています。このデータは「複製」されており、入力を検証する手順がある場合は保存する必要はありません。その手順が後で来る場合は、「非正規化」データを格納することが許可されます-再び、セマンティクスはそれを正当化し、モデルを正規化されたものとして見ることができます。(この概念に頭を包み込むことは有益です)
編集:
(2) の「非正規化」という用語は、正規形の正式な定義を見て、設計が正規形のいずれかを破る場合に非正規化されていると見なす場合は正しくありません (一部の人にとっては、これは明らかであり、それについての別の方法)。
それでも、多くの人が、必要のない無用なテキストではなく、データベースの冗長性を減らそうとするあらゆる努力に対して正規化という用語を使用するという考えに慣れたいと思うかもしれません (例として、次のような科学論文を見つけることができます)。派生属性を非正規化の形式と呼ぶのが一般的であるという警告として、それらが正しいに違いないとは言いません。ここを参照してください)。
より首尾一貫した認知された権威に言及したい場合 (すべての人に認知されているわけではありません)、おそらく CJDate の言葉で明確に区別できます。
設計理論の多くは、冗長性の削減に関係しています。正規化はrelvar内の冗長性を減らし、直交性はrelvar全体で冗長性を減らします。
データベースの詳細から引用: 実践者のためのリレーショナル理論
そして次のページで
完全に正規化しないと冗長性が生じ、特定の異常が発生する可能性があるのと同様に、直交性を順守しない場合も同様です。
したがって、relvar 間の冗長性の適切な用語は直交性です (基本的に、すべての正規形は単一の relvar について話しているため、正規化を厳密に見ても、2 つの異なる relvar 間の依存関係による改善を示唆することはありません)。
いずれにせよ、データベース設計を検討する際のその他の重要な概念の 1 つは、論理データベース モデルと物理データベース モデルの違いです。小計やインデックスを含むテーブルなど、物理レベルで役立つ多くのものは、モデル化しようとしている概念間の関係を確立して調査しようとする論理モデルには存在しません。だからこそ、それらは許容され、デザインを損なうものではないと言えます。
論理モデルと物理モデルの線が少しぼやけている場合があります。特に良い例は、小計を含むテーブルです。それを物理的な実装の一部と見なし、論理レベルで無視するには、次のことを行う必要があります。
- ユーザー (およびアプリケーション) が述語と一致しない方法で小計テーブルを直接更新できないようにする (つまり、小計手順にバグがある)
- ユーザー (およびアプリケーション) が、小計を更新せずにこれらが依存するテーブルを更新できないようにする (つまり、一部のアプリケーションは、合計を更新せずに詳細テーブルから行を削除しない)
上記のルールのいずれかを破ると、一貫性のない事実を提供する一貫性のないデータベースになってしまいます。(このような場合、発生した問題を修正または調査するための手順を正式に設計したい場合は、それを単なる追加のテーブルとは見なさず、論理レベルに存在するべきではありません)。
また、正規化は常に、モデル化しようとしているセマンティクスとビジネス ルールに依存します。たとえば、DBAPerformance はTaxAmount、トランザクション テーブルに を格納することは非正規化された設計ではない例を示していますが、モデル化しようとしているシステムの種類に依存することについて言及していません (それは明白ですか?)。たとえば、トランザクションに と呼ばれる別の属性がある場合、TaxRate通常は非正規化されます。これは、一連の非キー属性 (TaxAmount = Amount * TaxRate => FD: Amount,TaxRate -> TaxAmount) に機能的な依存関係があり、これらのうちの 1 つが必要なためです。削除されるか、一貫性が保証されます。
明らかに、あなたが構築しているシステムが監査会社向けである場合、機能的な依存関係がない可能性があります。彼らは、手計算を使用している、ソフトウェアに欠陥がある、または不完全なデータを記録する能力が必要な人を監査している可能性があります。計算自体が間違っている可能性もあり、監査法人としてその事実をありのままに記録しなければなりません。
したがって、要件によって決定されるセマンティクス (述語) は、関数の依存関係に影響を与えることによって、通常の形式のいずれかが壊れているかどうかに影響を与えます (言い換えれば、関数の依存関係を正しく確立することは、正規化されたデータベースを目指す場合のモデリングの非常に重要な部分です)。