ANTLR4を学習しようとしていますが、最初の実験で既にいくつかの問題が発生しています。
ここでの目標は、ANTLR を使用して QScintilla コンポーネントを構文強調表示する方法を学習することです。*.ini少し練習するために、ファイルを適切に強調表示する方法を学びたいと思いました。
まず、mcve を実行するには、次のものが必要です。
- antlr4 をダウンロードして動作することを確認し、メイン サイトの説明を読んでください。
- Python antlr ランタイムをインストールするには、次のようにします。
pip install antlr4-python3-runtime のレクサー/パーサーを生成し
ini.g4ます:grammar ini; start : section (option)*; section : '[' STRING ']'; option : STRING '=' STRING; COMMENT : ';' ~[\r\n]*; STRING : [a-zA-Z0-9]+; WS : [ \t\n\r]+;
実行することによってantlr ini.g4 -Dlanguage=Python3 -o ini
最後に、保存します
main.py:import textwrap from PyQt5.Qt import * from PyQt5.Qsci import QsciScintilla, QsciLexerCustom from antlr4 import * from ini.iniLexer import iniLexer from ini.iniParser import iniParser class QsciIniLexer(QsciLexerCustom): def __init__(self, parent=None): super().__init__(parent=parent) lst = [ {'bold': False, 'foreground': '#f92472', 'italic': False}, # 0 - deeppink {'bold': False, 'foreground': '#e7db74', 'italic': False}, # 1 - khaki (yellowish) {'bold': False, 'foreground': '#74705d', 'italic': False}, # 2 - dimgray {'bold': False, 'foreground': '#f8f8f2', 'italic': False}, # 3 - whitesmoke ] style = { "T__0": lst[3], "T__1": lst[3], "T__2": lst[3], "COMMENT": lst[2], "STRING": lst[0], "WS": lst[3], } for token in iniLexer.ruleNames: token_style = style[token] foreground = token_style.get("foreground", None) background = token_style.get("background", None) bold = token_style.get("bold", None) italic = token_style.get("italic", None) underline = token_style.get("underline", None) index = getattr(iniLexer, token) if foreground: self.setColor(QColor(foreground), index) if background: self.setPaper(QColor(background), index) def defaultPaper(self, style): return QColor("#272822") def language(self): return self.lexer.grammarFileName def styleText(self, start, end): view = self.editor() code = view.text() lexer = iniLexer(InputStream(code)) stream = CommonTokenStream(lexer) parser = iniParser(stream) tree = parser.start() print('parsing'.center(80, '-')) print(tree.toStringTree(recog=parser)) lexer.reset() self.startStyling(0) print('lexing'.center(80, '-')) while True: t = lexer.nextToken() print(lexer.ruleNames[t.type-1], repr(t.text)) if t.type != -1: len_value = len(t.text) self.setStyling(len_value, t.type) else: break def description(self, style_nr): return str(style_nr) if __name__ == '__main__': app = QApplication([]) v = QsciScintilla() lexer = QsciIniLexer(v) v.setLexer(lexer) v.setText(textwrap.dedent("""\ ; Comment outside [section s1] ; Comment inside a = 1 b = 2 [section s2] c = 3 ; Comment right side d = e """)) v.show() app.exec_()
すべてがうまくいけば、次の結果が得られるはずです。
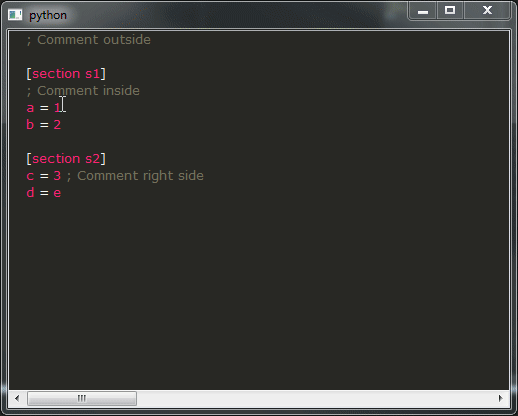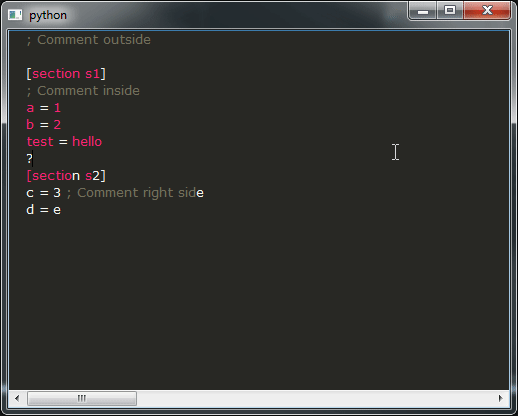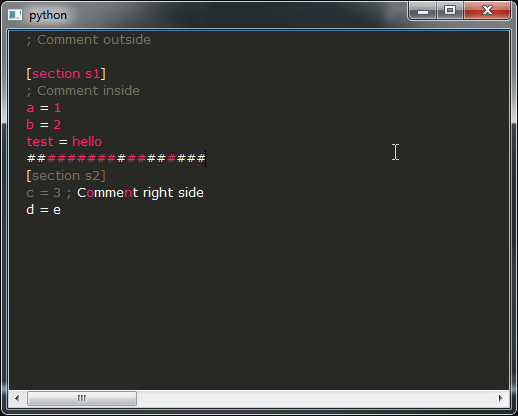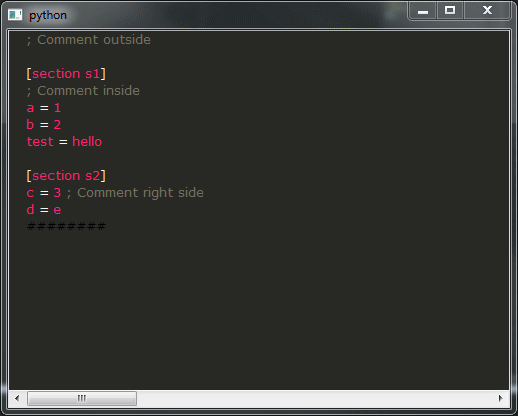
ここに私の質問があります:
- ご覧のとおり、デモの結果は使い物になるにはほど遠いものです。それは絶対に望んでいないことです。本当に気がかりです。代わりに、そこにあるすべての IDE と同様の動作を得たいと考えています。残念ながら、それを達成する方法がわかりません。そのような動作を提供するスニペットをどのように変更しますか?
- 現在、以下のスナップショットと同様の強調表示を模倣しようとしています。

そのスクリーンショットでは、強調表示が変数の割り当て (variable=deeppink および values=yellowish) で異なることがわかりますが、それを達成する方法がわかりません。このわずかに変更された文法を使用してみました:
grammar ini;
start : section (option)*;
section : '[' STRING ']';
option : VARIABLE '=' VALUE;
COMMENT : ';' ~[\r\n]*;
VARIABLE : [a-zA-Z0-9]+;
VALUE : [a-zA-Z0-9]+;
WS : [ \t\n\r]+;
次に、スタイルを次のように変更します。
style = {
"T__0": lst[3],
"T__1": lst[3],
"T__2": lst[3],
"COMMENT": lst[2],
"VARIABLE": lst[0],
"VALUE": lst[1],
"WS": lst[3],
}
しかし字句解析の出力を見ると、ANTLR 文法では順序が優先されるため、VARIABLEとの間に区別がないことがわかります。VALUES私の質問は、文法/スニペットをどのように変更して、そのような視覚的な外観を実現しますか?