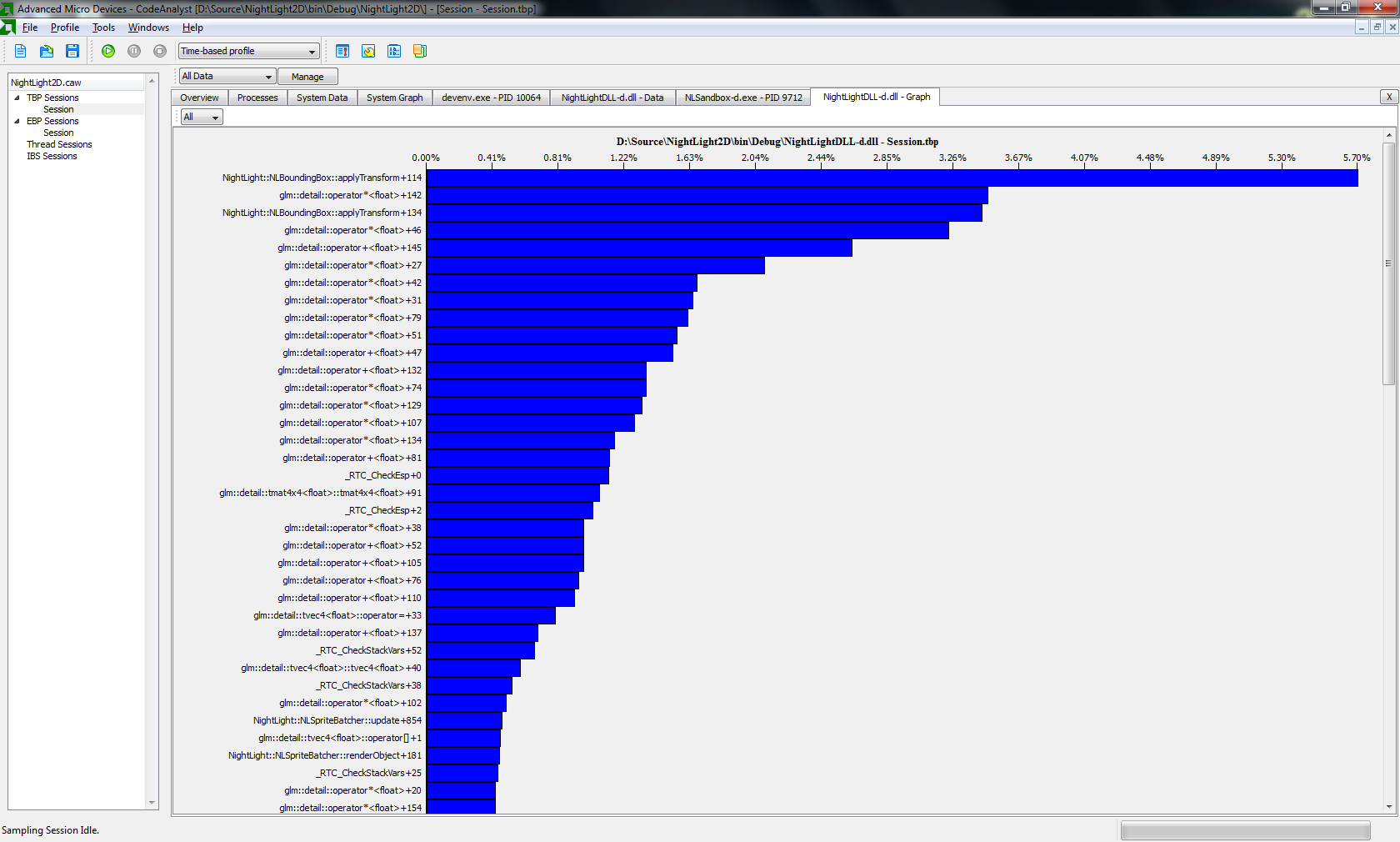
私はOpenGL32Dエンジンをプログラミングしています。現在、ボトルネックを解決しようとしています。したがって、AMDプロファイラーの次の出力をお願いします:http: //h7.abload.de/img/profilerausa.png
{kind=link}
データは数千のスプライトを使用して作成されました。
ただし、50.000スプライトでは、testappは5fpsではすでに使用できません。
これは、私のボトルネックが私が使用する変換関数であることを示しています。これは対応する関数です: http ://code.google.com/p/nightlight2d/source/browse/NightLightDLL/NLBoundingBox.cpp#130
void NLBoundingBox::applyTransform(NLVertexData* vertices)
{
if ( needsTransform() )
{
// Apply Matrix
for ( int i=0; i<6; i++ )
{
glm::vec4 transformed = m_rotation * m_translation * glm::vec4(vertices[i].x, vertices[i].y, 0, 1.0f);
vertices[i].x = transformed.x;
vertices[i].y = transformed.y;
}
m_translation = glm::mat4(1);
m_rotation = glm::mat4(1);
m_needsTransform = false;
}
}
すべてのスプライトを一度にバッチ処理しているため、シェーダーではそれを実行できません。つまり、変換を計算するためにCPUを使用する必要があります。
私の質問は:このボトルネックを解決するための最良の方法は何ですか?
私はスレッドATMを使用していません。そのため、vsyncを使用すると、画面が終了するのを待つため、パフォーマンスがさらに低下します。それは私がスレッドを使用する必要があることを教えてくれます。
もう1つの方法は、OpenCLを使用することです。CUDAは、私が知る限り、NVIDIAカードでのみ実行されるため、避けたいと思います。そうですか?
ポストスクリプト:
必要に応じて、ここからデモをダウンロードできます。
http://www63.zippyshare.com/v/45025690/file.html
これはプロファイラーを実行するためのデバッグバージョンであるため、VC++2008がインストールされている必要があることに注意してください。