行き詰まったように感じます、友達。「Pearls of Functional Algorithm Design」の第 11 章 (「最大セグメント合計ではない」) から方程式を選ぶことを誰かが説明してくれますか?
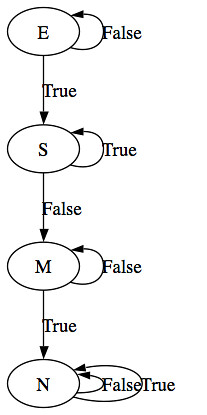
ここに問題があります (少し単純化されています) 与えられた遷移を持ついくつかの状態を考えてみましょう:
data State = E | S | M | N
deriving (Show, Eq)
step E False = E
step E True = S
step S False = M
step S True = S
step M False = M
step M True = N
step N False = N
step N True = N
それでは、pick を定義しましょう。
pick q = map snd . filter ((== q) . fst) . map (\a -> (foldl step E a, a))
著者は、次の 7 つの方程式が成り立つと主張しています。
pick E xs = [[]]
pick S [ ] = [ ]
pick S (xs ++ [x]) = map (++[x ]) (pick S xs ++ pick E xs)
pick M [ ] = [ ]
pick M (xs ++ [x ]) = pick M xs ++ pick S xs
pick N [ ] = [ ]
pick N (xs ++ [x]) = pick N xs ++ map (++[x]) (pick N xs ++ pick M xs)
誰か簡単な言葉で説明してくれませんか?なぜこれらの方程式が正しいのか、明らかな証明をどのように証明できるのでしょうか? S 方程式はほぼ理解できたように感じますが、全体としてこれはとらえどころのないままです。