http://farm8.staticflickr.com/7020/6702134377_cf70482470_z.jpg
{kind=link}
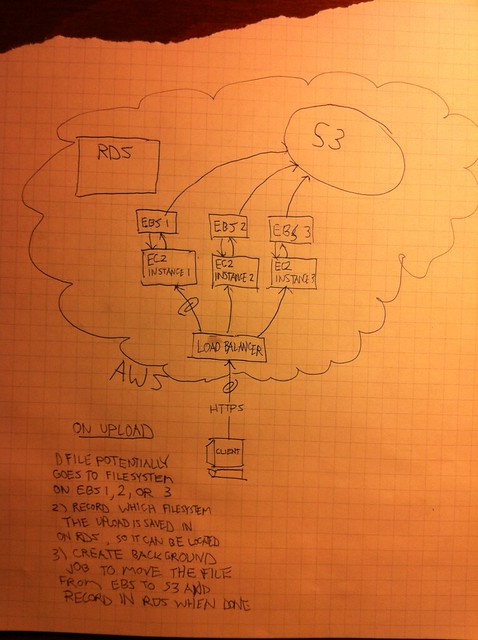
ひどい絵で申し訳ありませんが、私の考えを整理して伝えるためのより良い方法のように思えました. 私はしばらくの間、AWS のウェブアプリにファイルをアップロードするための最適な分離された簡単にスケーリング可能なシステムを作成する方法に取り組んできました。
S3 への直接アップロードは機能しますが、操作のためにアップローダがファイルに即座にアクセスできる必要があり、操作が完了すると、ファイルは s3 に移動し、そこですべてのインスタンスに提供されます。
glusterfs のようなもので SAN を作成し、そこに直接アップロードしてそこからサービスを提供するというアイデアを試しました。私はそれを除外していませんが、さまざまなソースから、このソリューションの信頼性は理想的ではない可能性があります (誰かがこれについてより良い洞察を持っているなら、私は聞きたいです)。いずれにせよ、私はより「すぐに使える」(AWS のコンテキストで) ソリューションを策定したいと考えていました。
この図を詳しく説明すると、たまたまアクセス先のインスタンスのローカル ファイルシステム (EBS ボリューム) にファイルをアップロードする必要があります。ファイルの保存場所は公開されません (つまり、 /tmp/uploads/ ) PHP の readfile() 操作を介してインスタンスからアクセスできるため、ユーザーはアップロード直後にファイルを表示して操作できます。ユーザーがファイルの操作を終了すると、ファイルを s3 に移動するメッセージが SQS のキューに入れられます。
私の質問は、ファイルをインスタンス(ロードバランサーのために任意のインスタンスである可能性があります)に「ローカルに」保存したら、それがどのインスタンス上にあるか(DB内)を記録して、PHPを介した後続のリクエストが読み取れるようにする方法ですまたはファイルを移動すると、そのファイルが見つかります。
これについてより多くの経験を持っている人が何らかの洞察を持っているなら、私は非常に感謝しています. ありがとう。