以前の回答を書き直して、それが最適である理由について詳しく説明します。
ウィキペディアから直接取得した A* アルゴリズムは次のとおりです。
function A*(start,goal)
closedset := the empty set // The set of nodes already evaluated.
openset := set containing the initial node // The set of tentative nodes to be evaluated.
came_from := the empty map // The map of navigated nodes.
g_score[start] := 0 // Distance from start along optimal path.
h_score[start] := heuristic_estimate_of_distance(start, goal)
f_score[start] := h_score[start] // Estimated total distance from start to goal through y.
while openset is not empty
x := the node in openset having the lowest f_score[] value
if x = goal
return reconstruct_path(came_from, came_from[goal])
remove x from openset
add x to closedset
foreach y in neighbor_nodes(x)
if y in closedset
continue
tentative_g_score := g_score[x] + dist_between(x,y)
if y not in openset
add y to openset
tentative_is_better := true
elseif tentative_g_score < g_score[y]
tentative_is_better := true
else
tentative_is_better := false
if tentative_is_better = true
came_from[y] := x
g_score[y] := tentative_g_score
h_score[y] := heuristic_estimate_of_distance(y, goal)
f_score[y] := g_score[y] + h_score[y]
return failure
function reconstruct_path(came_from, current_node)
if came_from[current_node] is set
p = reconstruct_path(came_from, came_from[current_node])
return (p + current_node)
else
return current_node
それでは、ここにすべての詳細を記入させてください。
heuristic_estimate_of_distanceは関数 Σ d(x i ) です。ここで、d(.) は各正方形 x iのゴール状態からのマンハッタン距離です。
というわけでセットアップ
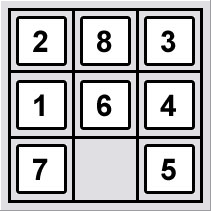
1 2 3
4 7 6
8 5
heuristic_estimate_of_distanced(.)=1 で 8,5 のそれぞれがゴール位置から 1 離れており、d(7)=2 で 7 がゴール状態から 2 離れているため、aは 1+2+1=4 になります。
A* が検索するノードのセットは、開始位置の後にすべての有効な位置が続くように定義されます。つまり、開始位置xが上記のようになっているとしましょう。
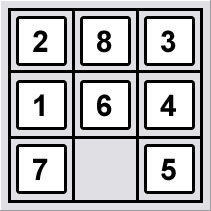
x =
1 2 3
4 7 6
8 5
次に、関数neighbor_nodes(x)は 2 つの有効な動きを生成します。
1 2 3
4 7
8 5 6
or
1 2 3
4 7 6
8 5
関数は、状態からdist_between(x,y)に遷移するために発生した四角移動の数として定義されます。これは、アルゴリズムの目的上、常に A* の 1 に等しくなります。xy
closedsetopensetどちらも A* アルゴリズムに固有であり、標準のデータ構造 (私が信じているプライオリティ キュー) を使用して実装できます。詳細はウィキペディアで見つけることができるcame_from関数 who を使用して見つかったソリューションを再構築するために使用されるデータ構造です。reconstruct_path解決策を覚えたくない場合は、これを実装する必要はありません。
最後に、最適性の問題について説明します。A* ウィキペディアの記事からの抜粋を考えてみましょう。
「ヒューリスティック関数 h が許容可能である場合、つまり、目標に到達するための実際の最小コストを過大評価しないことを意味し、閉集合を使用しない場合、A* 自体が許容可能 (または最適) です。閉集合が使用されている場合、 A* が最適であるためには、h も単調 (または一貫性) である必要があります. これは、d(x,y) がそれらの間のエッジの長さを表す場合、隣接するノード x と y の任意のペアについて、次の条件を満たさなければならないことを意味します: (x) <= d(x,y) +h(y)"
したがって、ヒューリスティックが許容可能で単調であることを示すだけで十分です。前者 (許容性) については、任意の構成が与えられた場合、ヒューリスティック (すべての距離の合計) は、各正方形が正当な移動のみによって制約されず、そのゴール位置に向かって自由に移動できると推定することに注意してください。これは明らかに楽観的な推定です。したがって、ヒューリスティック許容されます (または、目標位置に到達するには常に少なくともヒューリスティック推定と同じ数の移動が必要になるため、過大評価することはありません)。
単調性要件を言葉で表すと、「任意のノードのヒューリスティック コスト (目標状態までの推定距離) は、隣接するノードに遷移するコストにそのノードのヒューリスティック コストを加えた値以下でなければなりません。」
これは主に、関連のないノードへの遷移が、実際に遷移を行うコストよりも目標ノードまでの距離を縮める可能性がある負のサイクルの可能性を防ぐためのものであり、不十分なヒューリスティックを示唆しています。
私たちの場合、単調性を示すのは非常に簡単です。隣接するノード x,y は、d の定義により d(x,y)=1 になります。したがって、私たちは示す必要があります
h(x) <= h(y) + 1
これはと同等です
h(x) - h(y) <= 1
これはと同等です
Σ d(x i ) - Σ d(y i ) <= 1
これはと同等です
Σ d(x i ) - d(y i ) <= 1
neighbor_nodes(x)2 つの隣接ノード x、y の位置が最大で異なる 1 つの正方形の位置を持つことができるという定義により、合計で項が
d(x i ) - d(y i ) = 0
i の 1 つの値を除くすべての値。一般性を失うことなく、これは i=k に当てはまるとしましょう。さらに、i=k の場合、ノードは最大で 1 つの場所に移動したことがわかっているため、目標状態までの距離は、前の状態よりも最大で 1 つ大きくなければなりません。
Σ d(x i ) - d(y i ) = d(x k ) - d(y k ) <= 1
単調さを示しています。これは、何を表示する必要があるかを示しているため、このアルゴリズムが最適であることを証明しています (big-O 表記法または漸近的な方法で)。
big-O 記法に関しては最適性を示しましたが、ヒューリスティックを微調整するという点ではまだ多くの余地があることに注意してください。さらにひねりを加えて、目標状態までの実際の距離をより正確に見積もることができますが、ヒューリスティックが常に過小評価であることを確認する必要があります。そうしないと、最適性が失われます!
後で多くの月を編集する
これを(ずっと)後で読み直して、私が書いた方法が、このアルゴリズムの最適性の意味を混乱させていることに気付きました。
私がここで得ようとしていた最適性の 2 つの異なる意味があります。
1) アルゴリズムは最適解を生成します。これは、客観的な基準が与えられた場合に考えられる最善の解です。
2) アルゴリズムは、同じヒューリスティックを使用して、可能なすべてのアルゴリズムの最小数の状態ノードを展開します。
1) を取得するためにヒューリスティックの許容性と単調性が必要な理由を理解する最も簡単な方法は、A* をダイクストラの最短経路アルゴリズムのアプリケーションとして表示することです。ここで、エッジの重みは、これまでに移動したノード距離とヒューリスティックによって与えられます。距離。これらの 2 つのプロパティがなければ、グラフに負のエッジがあり、負のサイクルが発生する可能性があり、ダイクストラの最短経路アルゴリズムは正しい答えを返さなくなります! (自分自身を納得させるために、これの簡単な例を作成してください。)
2) 実際には理解するのが非常に紛らわしいです。この意味を完全に理解するために、このステートメントには多くの量指定子があります。たとえば、他のアルゴリズムについて話すときは、similarノードを展開し、アプリオリな情報なしで (ヒューリスティック以外の) 検索するアルゴリズムを A* と呼びます。明らかに、道のあらゆる段階で答えを教えてくれるオラクルや魔神など、ささいな反例を作成することもできます。この声明を深く理解するには、ウィキペディアの歴史セクションの最後の段落を読み、その慎重に述べられた文のすべての引用と脚注を調べることを強くお勧めします.
これにより、読者になる予定の読者の間で残っている混乱が解消されることを願っています.