antlrで解析ツリーからASTツリーに変換するための書き換えルールに問題があります。
これが私のantlrコードです:
grammar MyGrammar;
options {
output= AST;
ASTLabelType=CommonTree;
backtrack = true;
}
tokens {
NP;
NOUN;
ADJ;
}
//NOUN PHRASE
np : ( (adj)* n+ (adj)* -> ^(ADJ adj)* ^(NOUN n)+ ^(ADJ adj)* )
;
adj : 'adj1'|'adj2';
n : 'noun1';
「adj1noun1adj2」と入力すると、ツリーの解析結果は次のようになります。
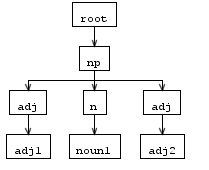
しかし、書き換えルール後のASTツリーは、解析ツリーとまったく同じではないように見えます。adjは二重であり、次のように順序付けられていません。
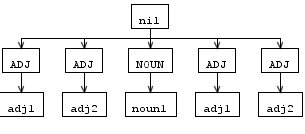
だから私の質問は、上記の解析ツリーのような結果を得るようにルールをどのように書き直すことができるかということです。