私は自分のカメラをスキャナーにしようとしています: 印刷されたテキストの写真を撮り、それらをビットマップに変換します (そして、djvuと OCR に変換します)。どのピクセルが白で、どのピクセルが黒であるかのしきい値を計算する必要がありますが、不均一な照明が原因で苦労しています。たとえば、中央のピクセルが十分に暗い場合、コーナーに黒いピクセルが集まってしまう可能性があります。
私がやりたいことは、比較的単純な仮定の下で、しきい値処理の前に不均一な照明を補正することです。より正確に:
1 つまたは 2 つの光源を想定します。1 つは表面全体で光強度が徐々に変化するもの (環境光) で、もう 1 つは逆二乗 (直接光) です。
紙の白い部分はすべて同じ反射率/アルベド/何であれ同じであると仮定します。
各ピクセルの照度を推定するアルゴリズムを見つけ、そこから各ピクセルの反射率を復元します。
ピクセルの反射率から、白か黒かを分類する
これを行うアルゴリズムの書き方がわかりません。照明を推定するときに暗いピクセルを無視したいので、最小二乗フィッティングに頼りたくありません。また、アルゴリズムが機能するかどうかもわかりません。
役立つアドバイスはすべて支持されます。
編集:私は間違いなく、画像を十分に大きい断片に切り刻むことを検討しました。これにより、「白い背景のテキスト」のように見えますが、単一の断片の照明が多かれ少なかれ均一になるように十分に小さくなります。次に、サブイメージの境界を越えて不連続性がないようにしきい値を補間すると、おそらく中途半端なものが得られると思います。これは良い提案であり、試してみる必要がありますが、それでも白と黒の境界線をどこに引くかという問題が残ります。さらに考えますか?
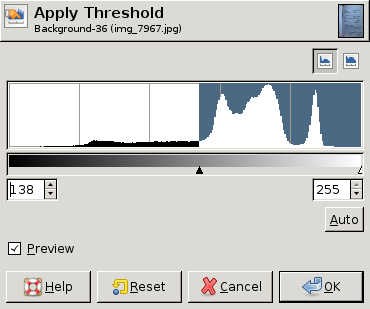
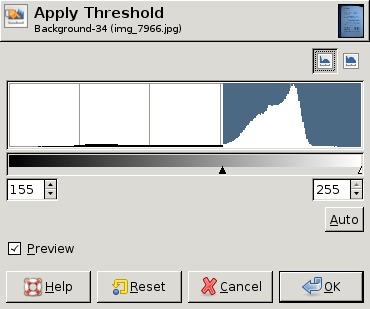
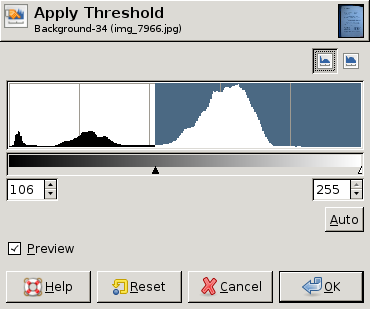
EDIT : これは、さまざまなヒストグラムと、各ヒストグラムの「最適な」しきい値 (手動で選択) を示す GIMP からのスクリーン ダンプです。3 つのうち 2 つでは、画像全体の単一のしきい値で十分です。ただし、3 番目の例では、左上隅に別のしきい値が必要です。