2 つの患者タイプ (患者 1 の 33) と (患者 2 の 99) で構成される 132 x 107 のデータセットがあります。
外れ値を探しているので、次のコマンドを使用して、データセットで pca を実行し、最初の 4 つのコンポーネントの qqplot を実行しました
pca = prcomp(data, scale. = TRUE)
plot(pca$x, pch = 20, col = c(rep("red", 33), rep("blue", 99)))
次を使用して2番目のコンポーネントのqqplotを実行すると:
qqPlot(pca$x[,2],pch = 20, col = c(rep("red", 33), rep("blue", 99)))
次のグラフは、2 つの明確な外れ値を示しています。左下隅の赤い点は患者 1 です。
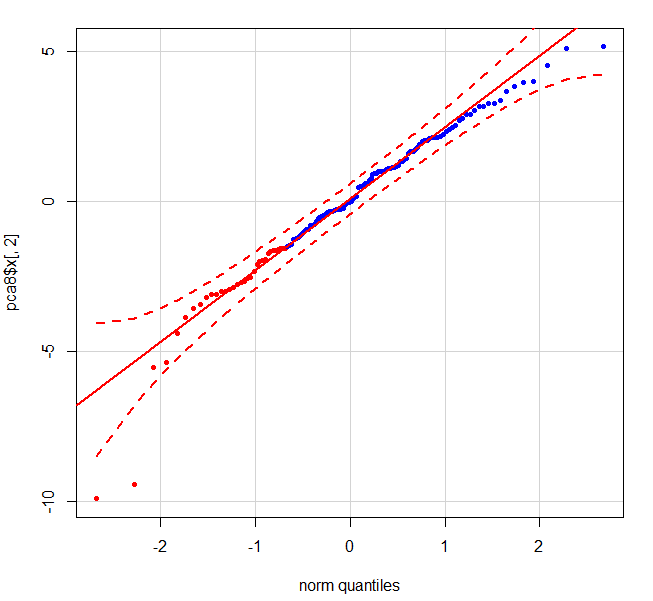
これらのポイントを削除できるように、データ内のこれらのポイントのインデックスを計算する簡単な方法はありますか?