宿題のために、テキストの単語の頻度をプロットし、それを最適なzipf分布と比較する必要があります。
ログロググラフのランクに従って、テキストのカウントされた単語頻度をプロットすると、うまくいくようです。
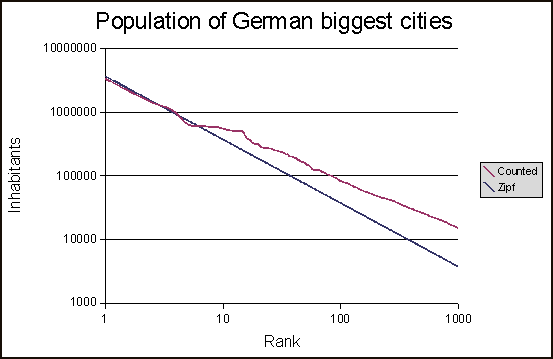
しかし、最適な zipf 分布の計算に問題があります。結果は次のようになります。
直線を計算するための式がどのようになるかわかりませんzipf。
zipf法律のドイツのウィキペディアのページで、うまくいくように見える方程式を見つけました

しかし、引用された情報源がないので、の定数がどこから来たのかわかりません1.78。
#tokenizes the file
tokens = word_tokenize(raw)
tokensNLTK = Text(tokens)
#calculates the FreqDist of all words - all words in lower case
freq_list = FreqDist([w.lower() for w in tokensNLTK]).most_common()
#Data for X- and Y-Axis plot
values=[]
for item in (freq_list):
value = (list(item)[1]) / len([w.lower() for w in tokensNLTK])
values.append(value)
#graph of counted frequencies gets plotted
plt.yscale('log')
plt.xscale('log')
plt.plot(np.array(list(range(1, (len(values)+1)))), np.array(values))
#graph of optimal zipf distribution is plotted
optimal_zipf = 1/(np.array(list(range(1, (len(values)+1))))* np.log(1.78*len(values)))###1.78
plt.plot(np.array(list(range(1, (len(values)+1)))), optimal_zipf)
plt.show()
このスクリプトを使用した結果は次のようになります。

しかし、最適なzipf分布が正しく計算されているかどうかはわかりません。もしそうなら、最適なzipf分布は X 軸を 1 点で横切るべきではないでしょうか?
編集:それが役立つ場合、私のテキストには2440400のトークンと27491のタイプがあります