これが私がいるシナリオです。
最新のレコードを照会する必要があるかなり大きなテーブルがあります。クエリの必須列の作成は次のとおりです。
CREATE TABLE [dbo].[ChannelValue](
[ID] [bigint] IDENTITY(1,1) NOT NULL,
[UpdateRecord] [bit] NOT NULL,
[VehicleID] [int] NOT NULL,
[UnitID] [int] NOT NULL,
[RecordInsert] [datetime] NOT NULL,
[TimeStamp] [datetime] NOT NULL
) ON [PRIMARY]
GO
ID 列は主キーであり、VehicleID と TimeStamp にはクラスター化されていないインデックスがあります
CREATE NONCLUSTERED INDEX [IX_ChannelValue_TimeStamp_VehicleID] ON [dbo].[ChannelValue]
(
[TimeStamp] ASC,
[VehicleID] ASC
)ON [PRIMARY]
GO
クエリを最適化するために取り組んでいるテーブルは 2,300 万行を少し超えており、クエリの操作に必要なサイズの 10 分の 1 にすぎません。
VehicleID ごとに最新の行を返す必要があります。
ここ StackOverflow でこの質問への回答を調べてきました。かなりの量のグーグルを実行しましたが、SQL Server 2005 以降でこれを行う一般的な方法が 3 つまたは 4 つあるようです。
これまでのところ、私が見つけた最速の方法は次のクエリです。
SELECT cv.*
FROM ChannelValue cv
WHERE cv.TimeStamp = (
SELECT
MAX(TimeStamp)
FROM ChannelValue
WHERE ChannelValue.VehicleID = cv.VehicleID
)
テーブル内の現在のデータ量では、実行に約 6 秒かかります。これは妥当な制限内ですが、ライブ環境でテーブルに含まれるデータ量では、クエリの実行が遅すぎます。
実行計画を見ると、SQL Server が行を返すために何をしているのかが気になります。
レピュテーションが十分に高くないため、実行計画の画像を投稿できませんが、インデックス スキャンがテーブル内のすべての行を解析しているため、クエリの速度が大幅に低下しています。
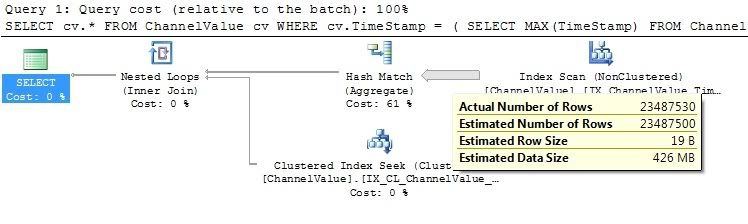
次のように SQL 2005 Partition メソッドを使用するなど、いくつかの異なる方法でクエリを書き直そうとしました。
WITH cte
AS (
SELECT *,
ROW_NUMBER() OVER(PARTITION BY VehicleID ORDER BY TimeStamp DESC) AS seq
FROM ChannelValue
)
SELECT
VehicleID,
TimeStamp,
Col1
FROM cte
WHERE seq = 1
しかし、そのクエリのパフォーマンスはさらに大幅に低下します。
このようにクエリを再構築しようとしましたが、結果の速度とクエリ実行計画はほぼ同じです。
SELECT cv.*
FROM (
SELECT VehicleID
,MAX(TimeStamp) AS [TimeStamp]
FROM ChannelValue
GROUP BY VehicleID
) AS [q]
INNER JOIN ChannelValue cv
ON cv.VehicleID = q.VehicleID
AND cv.TimeStamp = q.TimeStamp
テーブル構造に関してある程度の柔軟性を利用できるので (程度は限られていますが)、インデックス、インデックス付きビューなどを追加したり、データベースに追加のテーブルを追加したりできます。
ここで何か助けていただければ幸いです。
編集実行計画の画像へのリンクを追加しました。