処理しているデータの種類はわかりませんが、音声データの処理に使用した方法で、極大値を見つけるのに役立ちます。信号処理ツールボックスの3つの関数、HILBERT、BUTTER、およびFILTFILTを使用します。
data = (...the waveform of noisy data...);
Fs = (...the sampling rate of the data...);
[b,a] = butter(5,20/(Fs/2),'low'); % Create a low-pass butterworth filter;
% adjust the values as needed.
smoothData = filtfilt(b,a,abs(hilbert(data))); % Apply a hilbert transform
% and filter the data.
次に、 smoothDataで最大値の検索を実行します。HILBERTを使用すると、最初にデータに正のエンベロープが作成され、次にFILTFILTがBUTTERのフィルター係数を使用してデータエンベロープをローパスフィルター処理します。
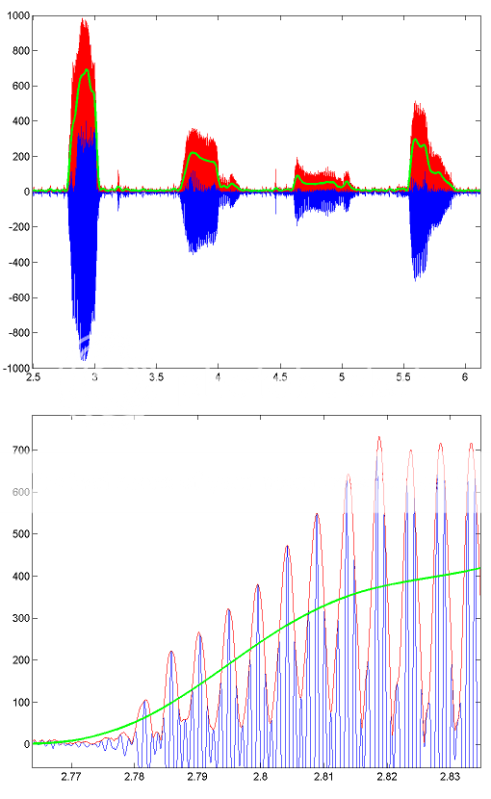
この処理がどのように機能するかの例として、録音された音声のセグメントの結果を示すいくつかの画像があります。青い線は元の音声信号、赤い線はエンベロープ(HILBERTを使用して取得)、緑の線はローパスフィルター処理された結果です。下の図は、最初の拡大版です。
試してみるランダム:
これは私が最初に思いついたランダムなアイデアでした...最大値の最大値を見つけることによってプロセスを繰り返すことを試みることができます:
index = find(diff(sign(diff([0; x(:); 0]))) < 0);
maxIndex = index(find(diff(sign(diff([0; x(index); 0]))) < 0));
ただし、信号対雑音比によっては、関心のある極大値を取得するためにこれを何回繰り返す必要があるかは不明です。これは、ランダムな非フィルタリングオプションです。=)
マキシマファインディング:
念のために言っておきますが、私が見たもう1つの1行の最大値検出アルゴリズム(リストしたものに加えて)は次のとおりです。
index = find((x > [x(1) x(1:(end-1))]) & (x >= [x(2:end) x(end)]));