NVIDIA は、メモリ転送のオーバーヘッドを削減するためにGPUDirectを提供しています。AMD/ATI に同様の概念があるかどうか疑問に思っていますか? 具体的には:
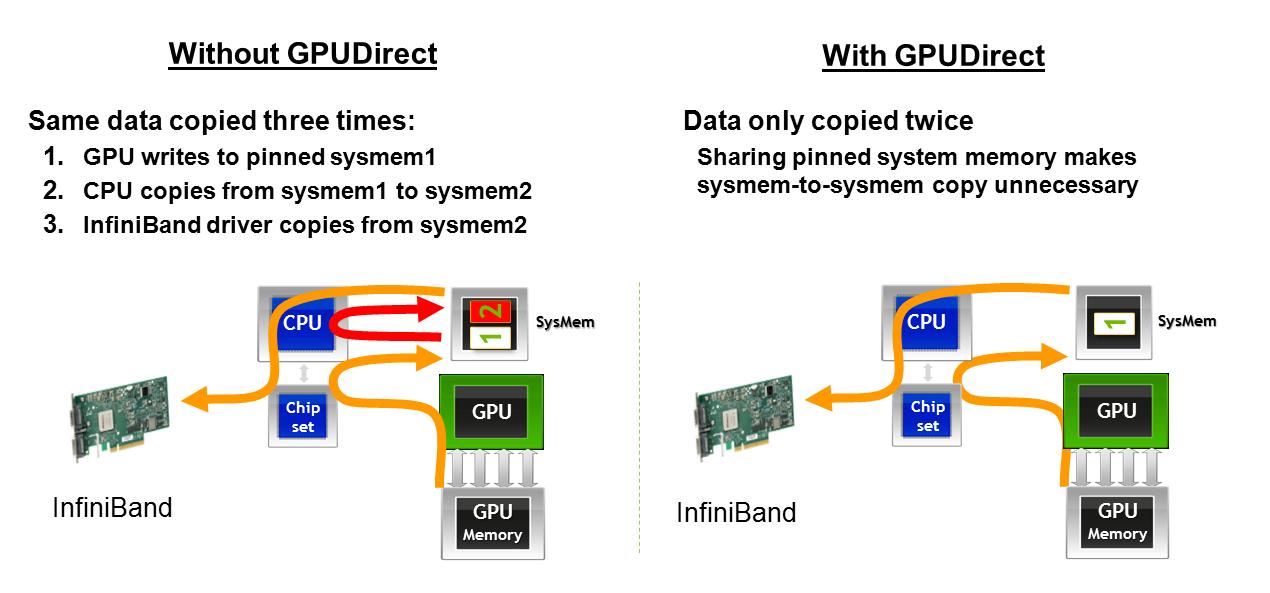
1)ここで説明されているように、AMD GPU はネットワーク カードと接続するときに 2 番目のメモリ転送を回避しますか。ある時点でグラフィックが失われた場合に備えて、1 台のマシン上の GPU からデータを取得してネットワーク インターフェイス経由で転送する際の GPUDirect の影響について説明します。インターフェースカード。GPUDirect がない場合、GPU メモリは 1 つのアドレス空間でホスト メモリに移動し、CPU はメモリを別のホスト メモリ アドレス空間にコピーするためにコピーを実行する必要があります。その後、ネットワーク カードに移動できます。
{kind=link}
2)ここで説明されているように、2 つの GPU が同じ PCIe バスで共有されている場合、AMD GPU は P2P メモリ転送を許可しますか? ある時点でグラフィックが失われた場合に備えて、同じ PCIe バス上の GPU 間でデータを転送する際の GPUDirect の影響について説明します。GPUDirect を使用すると、ホスト メモリに触れることなく、同じ PCIe バス上の GPU 間でデータを直接移動できます。GPUDirect を使用しない場合、GPU がどこにあるかに関係なく、データは別の GPU に到達する前に常にホストに戻る必要があります。
{kind=link}
編集: ところで、GPUDirect のどの程度がベーパーウェアであり、実際にどれだけ有用かは完全にはわかりません。GPU プログラマーがそれを実際に何かに使用しているという話は聞いたことがありません。これについての考えも大歓迎です。