問題タブ [gpudirect]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
cuda - AMD の OpenCL は CUDA の GPUDirect に似たものを提供しますか?
NVIDIA は、メモリ転送のオーバーヘッドを削減するためにGPUDirectを提供しています。AMD/ATI に同様の概念があるかどうか疑問に思っていますか? 具体的には:
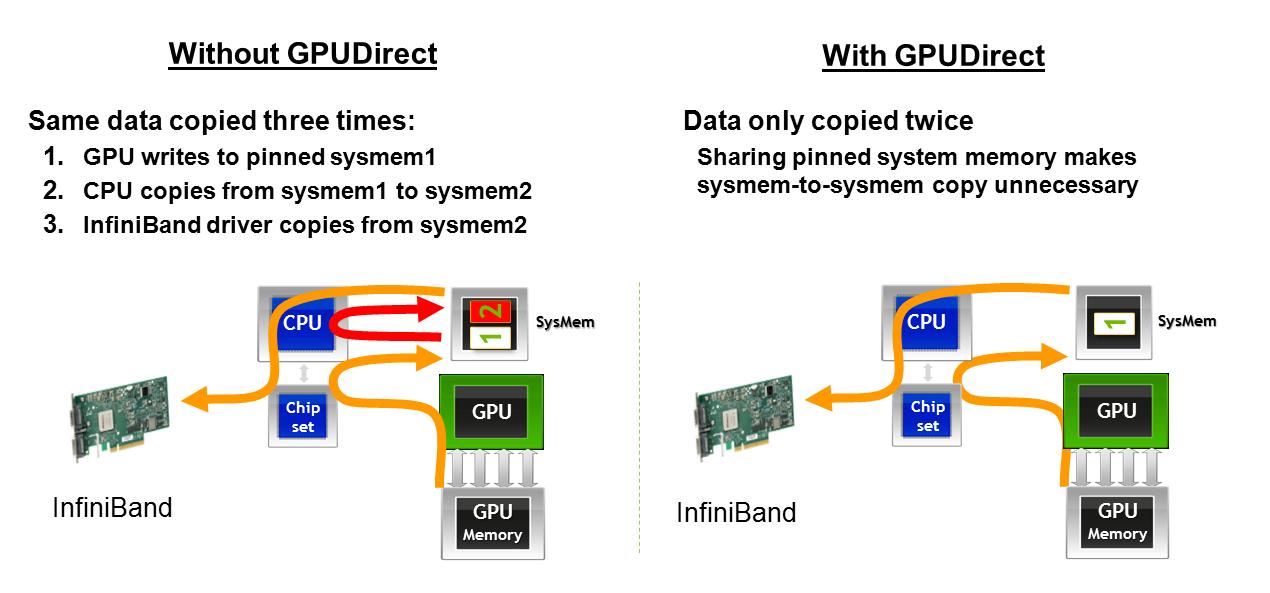
1)ここで説明されているように、AMD GPU はネットワーク カードと接続するときに 2 番目のメモリ転送を回避しますか。ある時点でグラフィックが失われた場合に備えて、1 台のマシン上の GPU からデータを取得してネットワーク インターフェイス経由で転送する際の GPUDirect の影響について説明します。インターフェースカード。GPUDirect がない場合、GPU メモリは 1 つのアドレス空間でホスト メモリに移動し、CPU はメモリを別のホスト メモリ アドレス空間にコピーするためにコピーを実行する必要があります。その後、ネットワーク カードに移動できます。
{kind=link}
2)ここで説明されているように、2 つの GPU が同じ PCIe バスで共有されている場合、AMD GPU は P2P メモリ転送を許可しますか? ある時点でグラフィックが失われた場合に備えて、同じ PCIe バス上の GPU 間でデータを転送する際の GPUDirect の影響について説明します。GPUDirect を使用すると、ホスト メモリに触れることなく、同じ PCIe バス上の GPU 間でデータを直接移動できます。GPUDirect を使用しない場合、GPU がどこにあるかに関係なく、データは別の GPU に到達する前に常にホストに戻る必要があります。
{kind=link}
編集: ところで、GPUDirect のどの程度がベーパーウェアであり、実際にどれだけ有用かは完全にはわかりません。GPU プログラマーがそれを実際に何かに使用しているという話は聞いたことがありません。これについての考えも大歓迎です。
cuda - GPUからリモートホストへのGPUDirectRDMA転送
シナリオ:
Infinibandに接続されたクライアントとサーバーの2台のマシンがあります。サーバーマシンにはNVIDIAFermiGPUがありますが、クライアントマシンにはGPUがありません。いくつかの計算にGPUを使用するGPUマシンで実行されているアプリケーションがあります。GPU上の結果データは、サーバーマシンによって使用されることはなく、代わりに処理なしでクライアントマシンに直接送信されます。現在cudaMemcpy、GPUからサーバーのシステムメモリにデータを取得し、ソケットを介してクライアントに送信しています。この通信でRDMAを有効にするためにSDPを使用しています。
質問:
cudaMemcpyこの状況で、NVIDIAのGPUDirectテクノロジーを利用して通話を取り除くことは可能ですか?GPUDirectドライバーが正しくインストールされていると思いますが、最初にホストにコピーせずにデータ転送を開始する方法がわかりません。
SDPをGPUDirectと組み合わせて使用することはできないと思いますが、サーバーマシンのGPUからクライアントマシンへのRDMAデータ転送を開始する他の方法はありますか?
ボーナス: GPUDirectの依存関係が正しくインストールされているかどうかをテストする簡単な方法が誰かにある場合は、それも役立ちます!
cuda - CUDA: GeForce GTX 690 上の GPUDirect
GeForce GTX 690 (Zotac や EVGA などのベンダー製) は、Tesla K10 のように CUDA プログラミングに使用できます。
質問: GeForce GTX 690 は GPUDirect をサポートしていますか? 具体的には、2 枚の GTX 690 カードを使用する場合、4 つの GPU (各カード内に 2 つの GPU) を持つことになります。両方の GTX 690 カードを同じ PCIe スイッチに接続した場合、GPUDirect は 4 つの GPU の任意のペア間の通信でうまく機能しますか?
ありがとう。
cuda - nVidia RDMA GPUDirect は常に物理アドレスのみ (CPU の物理アドレス空間内) で動作しますか?
私たちが知っているように:http://en.wikipedia.org/wiki/IOMMU#Advantages
周辺メモリのページングは IOMMUでサポートできます。PCI-SIG PCIe アドレス変換サービス (ATS) ページ要求インターフェイス (PRI) 拡張機能を使用する周辺機器は、メモリ マネージャー サービスの必要性を検出して通知できます。

しかし、CUDA >= 5.0 で nVidia GPU を使用すると、RDMA GPUDirect を使用でき、次のことがわかります。
http://docs.nvidia.com/cuda/gpudirect-rdma/index.html#how-gpudirect-rdma-works
従来、BAR ウィンドウなどのリソースは、CPU の MMU をメモリ マップド I/O (MMIO) アドレスとして使用して、ユーザーまたはカーネル アドレス空間にマップされていました。ただし、現在のオペレーティング システムにはドライバー間で MMIO 領域を交換するための十分なメカニズムがないため、NVIDIA カーネル ドライバーは関数をエクスポートして、必要なアドレス変換とマッピングを実行します。
http://docs.nvidia.com/cuda/gpudirect-rdma/index.html#supported-systems
GPUDirect の RDMA は現在、PCI デバイスの観点から見て、すべての物理アドレスが同じであることに依存しています。これにより IOMMU との互換性がなくなるため、RDMA for GPUDirect が機能するように IOMMU を無効にする必要があります。
CPU-RAM を UVA に割り当ててマッピングすると、次のようになります。
Windwos7x64 で等しいポインターを取得します。つまり、cudaHostGetDevicePointer()何もしません。
host_src_ptr = 68719476736
uva_src_ptr = 68719476736
「ドライバー間でMMIO領域を交換するための十分なメカニズム」とはどういう意味ですか、ここでどのようなメカニズムが意味されているのか、仮想アドレスを使用してPCIe経由でBARの物理領域にアクセスすることでIOMMUを使用できない理由-PCIeを介した別のメモリマップデバイス?
これは、RDMA GPUDirect が常に (CPU の物理アドレス空間内の) 物理アドレスのみを操作することを意味しますが、CPU の仮想アドレス空間内の単純なポインターにuva_src_ptr等しいカーネル関数に送信するのはなぜですか?host_src_ptr
gpu - GPUDirect が共有デバイスで分離を強制する方法
GPUDirect についてhttps://developer.nvidia.com/gpudirectを読んでいます。この例では、2 つの GPU と CPU と共に PCIe に接続されたネットワーク カードがあります。
ネットワーク デバイスにアクセスしようとするすべてのクライアント間で、分離はどのように実施されますか? それらはすべてデバイスの同じ PCI BAR にアクセスしていますか?
ネットワーク デバイスは、ある種の SR-IOV メカニズムを使用して分離を強制していますか?
cuda - GPUDirect 2.0 P2P 経由のリモート GPU-RAM で CUDA アトミック操作を使用できますか?
たとえば、グローバル メモリ (GPU-RAM) で CUDA アトミック操作、、... を使用できatomicAdd(ptr, val)ますatomicCAS(ptr, old, new)。CUDA 6.5 を使用。
しかし、これらのアトミック操作をGPUDirect 2.0 P2P経由でリモート グローバル メモリに使用できますか?
cuda - Infiniband で GPUDirect RDMA を使用する方法
私は2台のマシンを持っています。各マシンには複数のテスラ カードがあります。各マシンには InfiniBand カードもあります。InfiniBand を介して、異なるマシン上の GPU カード間で通信したいと考えています。ポイントツーポイントのユニキャストで十分です。余分なコピー操作を省けるように、GPUDirect RDMA を確実に使用したいと考えています。
現在、Mellanox から InfiniBand カード用のドライバーが提供されていることは承知しています。ただし、詳細な開発ガイドは提供していません。また、OpenMPI が私が求めている機能をサポートしていることも認識しています。しかし、OpenMPI はこの単純なタスクには重すぎて、1 つのプロセスで複数の GPU をサポートしていません。
ドライバを直接使って通信を行う方法について何か助けが得られないだろうか。コードサンプル、チュートリアル、なんでもいいです。また、OpenMPI でこれを処理するコードを見つけるのを手伝ってくれる人がいれば幸いです。