問題タブ [data-structures]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
data-structures - ウィキペディアの不均衡なAVLツリーの例は実際にはどのように不均衡ですか?
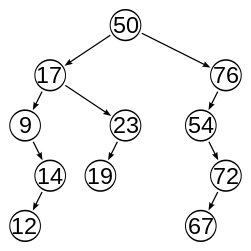
上の画像は、ウィキペディアが不均衡であると示している「AVLツリーに関するウィキペディアのエントリ」からのものです。この木はどうしてまだバランスが取れていないのですか?記事からの引用は次のとおりです。
ノードのバランス係数は、右側のサブツリーの高さから左側のサブツリーの高さを引いたものであり、バランス係数が1、0、または-1のノードはバランスが取れていると見なされます。他のバランス係数を持つノードは不均衡と見なされ、ツリーのバランスを取り直す必要があります。バランス係数は、各ノードに直接格納されるか、サブツリーの高さから計算されます。
左と右の両方のサブツリーの高さは4です。左のツリーの右のサブツリーの高さは3ですが、それでも4より1つ少ないだけです。誰かが私が欠けているものを説明できますか?
data-structures - スキップリスト-これまでに使用したことがありますか?
ここの誰かがスキップリストを使ったことがあるかどうか疑問に思います。平衡二分木とほぼ同じ利点があるように見えますが、実装は簡単です。持っている場合、あなたはあなた自身を書いたのですか、それとも事前に書かれたライブラリを使用しましたか(もしそうなら、その名前は何でしたか)?
data-structures - オブジェクトを移動するための空間データ構造?
多くの移動オブジェクト (球体、三角形、ボックス、点など) を処理するのに最適なデータ構造は何だろうと考えていました。Nearest Neighbor と Collsion detection という 2 つの質問に答えようとしています。
伝統的に、R ツリーのようなデータ構造は最近傍クエリに使用され、Oct/Kd/BSP は静的オブジェクトまたは非常に少数の移動オブジェクトを扱う衝突検出問題に使用されることを認識しています。
他にもっと良いものがあることを願うばかりです。
私はすべての助けに感謝します。
c++ - std::vector と std::list と std::slist の相対的なパフォーマンスは?
リスト要素へのランダムアクセスが要件ではない単純なリンクリストの場合、std::list代わりに使用することには大きな利点(パフォーマンスまたはその他)がありstd::vectorますか? std::slist後方トラバーサルが必要な場合、要素を反復処理する前にreverse()リストを使用する方が効率的でしょうか?
c++ - ユーザー定義型の CArray をソートするにはどうすればよいですか?
C++でCArrayをソートする組み込みの方法はありますか?
algorithm - ハッシュ テーブルとトライ (プレフィックス ツリー) のどちらを選択するか
したがって、ハッシュテーブルまたはプレフィックスツリーのどちらかを選択する必要がある場合、どちらかを選択するように導く識別要因は何ですか. 私自身の素朴な観点からは、トライを使用すると、配列として保存されないため、余分なオーバーヘッドがあるように見えますが、実行時間の観点からは(最長のキーが最長の英単語であると仮定して)、本質的に O になる可能性があります(1) (上限に関して)。たぶん、最も長い英単語は50文字ですか?
ハッシュ テーブルは、インデックスを取得するとすぐに検索されます。ただし、インデックスを取得するためにキーをハッシュすると、50 近くの手順を簡単に実行できるように思えます。
誰かがこれについてより経験豊富な視点を提供できますか? ありがとう!
c - Cの悪い習慣で柔軟な配列メンバーを使用していますか?
私は最近、C で柔軟な配列メンバーを使用することは、ソフトウェア エンジニアリングの実践として不適切であると読みました。しかし、その声明はいかなる議論にも裏付けられていませんでした。これは受け入れられた事実ですか?
(柔軟な配列メンバーは、C99 で導入された C の機能であり、最後の要素を未指定のサイズの配列として宣言できます。例: )
algorithm - 反転可能なデータ構造のパターン名?
私が設計しているクラス内で何が起こっているかを正確に伝える命名規則を考えようとしています。二次的な注意として、私は 2 つのほぼ同等のユーザー API のどちらかを決定しようとしています。
状況は次のとおりです。
中心的なデータ構造の 1 つに、1) 蓄積、2) 分析、3) クエリ実行の 3 つのフェーズがある科学アプリケーションを構築しています。
私の場合、これは空間モデリング構造であり、内部で KDTree を使用して 3 次元空間内のポイントのコレクションを分割します。各ポイントは、周囲環境の 1 つまたは複数の属性を表し、測定自体について一定レベルの信頼性があります。
コレクションに (場合によっては多数の) 測定値を追加した後、オブジェクトの所有者は、該当するフィールド内のどこかにある新しいデータ ポイントで内挿された測定値を取得するためにクエリを実行します。
API は次のようになります (コードは Java ですが、それほど重要ではありません。わかりやすくするために、コードは 3 つのセクションに分かれています)。
私の特定の問題ドメインでは、SECTION 2 で少量の増分作業 (ポイントをバランスの取れた KDTree に分割する) を実行できます。
また、SECTION 3 で発生する可能性のある少量の作業 (いくつかの線形補間の実行) があります。
しかし、セクション 2 と 3の間で実行しなければならない膨大な量の作業 (テイラー級数とエルミート関数を使用して、カーネル密度推定器を構築し、高速ガウス変換を実行しますが、それはまったく的外れです) があります。
過去に、データ構造を構築するために遅延評価を使用したことがありました (この場合は、「interpolateAt」メソッドの最初の呼び出し時です)。しかし、ユーザーが「field.add」を呼び出すと、 ()" メソッドをもう一度使用すると、それらのデータ構造を完全に破棄して、最初からやり直す必要があります。
他のプロジェクトでは、ユーザーが明示的に「object.flip()」メソッドを呼び出して、「追加モード」から「クエリ モード」に切り替える必要がありました。このような設計の良いところは、ハードコア計算が開始される正確な瞬間をユーザーがより適切に制御できることです。しかし、API コンシューマがオブジェクトの現在のモードを追跡するのは面倒です。さらに、標準的な使用例では、クエリの発行を開始した後、呼び出し元がコレクションに別の値を追加することはありません。ほとんどの場合、データ集計はクエリの準備よりも完全に優先されます。
このようなデータ構造の設計をどのように処理しましたか?
新しいデータがコレクションに入ったときに中間データ構造を捨てて、オブジェクトにその重い分析を怠惰に実行させたいですか? それとも、データ構造を追加モードから照会モードに明示的に切り替えるようにプログラマーに要求しますか?
そして、このようなオブジェクトの命名規則を知っていますか? 私が考えていないパターンはありますか?
編集時:
この例で使用した「ContinuousScalarField」という名前のクラスについては、混乱と好奇心があるようです。
これらのウィキペディアのページを読むと、私が話していることのかなり良いアイデアを得ることができます:
地形図を作成したいとしましょう (これは私の正確な問題ではありませんが、概念的には非常に似ています)。したがって、1 平方マイルの領域で 1,000 の高度測定を行いますが、測量機器には標高でプラスまたはマイナス 10 メートルの誤差があります。
すべてのデータ ポイントを収集したら、値を補間するだけでなく、各測定のエラーも考慮に入れるモデルにそれらをフィードします。
トポ マップを描画するには、ピクセルを描画する各ポイントの標高をモデルにクエリします。
単一のクラスがクエリの追加と処理の両方を担当する必要があるかどうかという質問については、100% 確信はありませんが、そうだと思います。
同様の例を次に示します。HashMap クラスと TreeMap クラスを使用すると、オブジェクトの追加とクエリの両方を実行できます。追加とクエリのための個別のインターフェイスはありません。
クエリ メカニズムをサポートするために内部データ構造を継続的に維持する必要があるため、どちらのクラスも私の例に似ています。HashMap クラスは定期的に新しいメモリを割り当て、すべてのオブジェクトを再ハッシュし、オブジェクトを古いメモリから新しいメモリに移動する必要があります。TreeMap は、赤黒木データ構造を使用して、木のバランスを継続的に維持する必要があります。
唯一の違いは、データ セットが閉じていることがわかったら、すべての計算を実行できる場合に、クラスが最適に実行されることです。
.net - Enum を使用するか、データベース内のテーブルにクエリを実行する必要がありますか?
私のデータベースには、たとえばタイプを定義するテーブルがあります
表: パブリケーションの種類
ID キーを介して、フィールドTypeIDを持つパブリケーション テーブルに関連付けられます。
次に、パブリケーション タイプに基づいてフィルター処理する .NET アプリケーションで PublicationTable データ テーブルを作成します。たとえば、次の関数は、特定の著者と出版タイプの出版数を示します。
この関数を呼び出して、特定のタイプの著者による記事の数を取得するには、
2 つの整数で関数を呼び出す
countPublications(著者ID, 1)
書くことができるように列挙型をセットアップします
countPublications(authorID, pubType.Article)
また
どうにかしてパブリケーション タイプ テーブルを使用してパブリケーション データ セットをフィルタリングしますが、これを行う方法がわかりません。
他にどのようなアプローチを検討する必要がありますか。
ありがとう
python - Pythonのリストメソッドappendとextendの違いは何ですか?
append()list メソッドとの違いは何extend()ですか?