問題タブ [linguistics]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
java - Javaで文の論理部分を取得する方法は?
文があるとしましょう:
に変更する
文の意味を壊さず、それはまだ有効です。他の方法で単語をシャッフルすると、奇妙な文から無効な文が生成されます。つまり、基本的には、情報をより具体的にする文の一部について話しているのですが、それらを削除しても文全体が壊れることはありません。そのような部分を識別することができるNLPライブラリはありますか?
parsing - 文字およびテキスト処理のリソース (エンコード、正規表現、NLP)
エンコーディング、文字、テキストの基礎を学びたいです。これらを理解することは、それがログ ファイルであろうと集合知のアルゴリズムを構築するためのテキスト ソースであろうと、大量のテキスト セットを処理するために重要です。私の今の知識は、「UTF-8さえ使えば大丈夫」というようなごく基本的なことです。
高度なトピックについてすぐに学ぶ必要があるとは言いません。しかし、私は知る必要があります:
- エンコーディングに関するビットおよびバイトレベルの知識。
- 英語で使用されていない文字とアルファベット。
- マルチバイトエンコーディング。(私は中国語と日本語をある程度理解しています。そしてそれらを解析することは重要です。)
- 正規表現。
- テキスト処理のアルゴリズム。
- 自然言語の解析。
また、数学とコーパス言語学の理解も必要です。現在および将来の Web (セマンティック、インテリジェント、リアルタイム Web) には、大きなテキストの処理、解析、および分析が必要です。
いくつかの弾丸を使い始めるためのリソース (おそらく本?) を探しています。(スタック オーバーフローでは、正規表現に関する有益な議論が数多く見つかります。そのため、そのトピックに関するリソースを提案する必要はありません。)
php - 間違った単語phpから正しい単語を取得.
間違った単語から正しい単語を取得する方法を知りたい...
例
文字列は「sstring」です
しかし、正しい単語は文字列です...
PHPのアルゴリズムはありますか?
感謝と前進
latex - LaTeX の 2 行バイリンガル段落
行間の光沢を使用して、ドキュメントの翻訳をレイアウトできます。
http://en.wikipedia.org/wiki/Interlinear_gloss
通常、これは単語ごとまたは形態素ごとに行われます。しかし、私はこれを別の方法で、一度に段落全体を翻訳したいと考えています。次のリンクと画像は、私がやりたいことの例ですが、より大きな別のテキストに対してやりたいと思っています。
http://www.optimnem.co.uk/learning/spanish/three-little-pigs.php
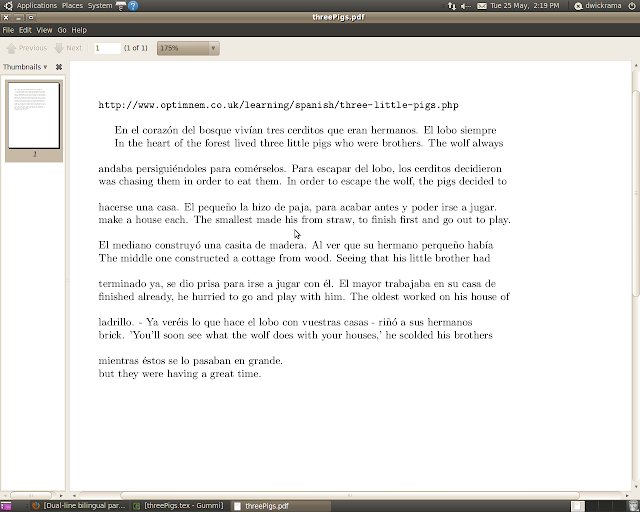
今のところ、言語間で順序が変わる単語やフレーズの順序を考慮することに興味はありません。つまり、段落内の単語が揃っていなくても、または 1 つの段落の長さが他の段落よりもはるかに長く、行がはみ出していてもかまいません。
私の知る限り、次のパッケージは私のニーズを満たしていません。
英語版は次のとおりです。
スペイン語版は次のとおりです。
私はこのように手動でやりたくありません:
パッケージまたはマクロを使用して、それぞれの行末に達したときに、英語とスペイン語のテキストに改行を自動的に挿入したいと考えています。この単純な 2 行バイリンガルの段落を Latex でより自動化された方法で (手動で改行を追加せずに) レイアウトするにはどうすればよいですか?
linguistics - 英語を活用するためのソフトウェア
次のことができるソフトウェアはありますか?
のような英文が与えられた場合
「彼はベイクドビーンズが好きです」、
「彼」を「私」に変えると文は
「ベイクドビーンズが好き」
(Sに注意してください)
また
「彼女は髪をポニーテールにしている」
「彼女」を「彼」に変えると文は
「彼は髪をポニーテールにしている」.
同様に、文を過去形に変えることができます。
「彼女は髪をポニーテールにしていた」.
そのようなソフトウェアは存在しますか?
php - ベイズ分類器の PHP 実装: トピックをテキストに割り当てる
私のニュース ページ プロジェクトには、次の構造を持つデータベース テーブルnewsがあります。
さらに、単語の頻度に関する情報を含むテーブルベイがあります。
ここで、PHP スクリプトですべてのニュース エントリを分類し、いくつかの可能なカテゴリ (トピック) の 1 つをそれらに割り当てたいと考えています。
これは正しい実装ですか?改善できますか?
トレーニングは手動で行われ、このコードには含まれていません。「不動産を売ればお金を稼ぐことができる」というテキストがカテゴリ/トピック「経済」に割り当てられている場合、すべての単語 (you,can,make,...) が「経済」のテーブルベイに挿入されます。トピックと 1が標準カウントです。単語が同じトピックとの組み合わせで既に存在する場合、カウントがインクリメントされます。
サンプル学習データ:
単語のトピック数
カチンスキー 政治 1
ソニーテクノロジー1
銀行経済学1
電話技術 1
ソニー経済学3
エリクソンテクノロジー2
サンプル出力/結果:
テキストのタイトル: 電話テスト Sony Ericsson Aspen - 敏感な Winberry
政治
....電話 ....テスト ....ソニー ....エリクソン ....アスペン ....センシティブ ....ウィンベリー
テクノロジー
....phone FOUND ....test ....sony FOUND ....ericsson FOUND ....aspen ....sensitive ....winberry
経済
....電話 ....test ....sony FOUND ....ericsson ....aspen ....sensitive ....winberry
結果: テキストはトピック Technology に属し、可能性は 0.013888888888889 です。
事前にどうもありがとうございました!
python - Justadistraction: 空白のない英語のトークン化。村上ひつじ男
空白が削除された場合、英語 (または他の西洋言語) の文字列をどのようにトークン化するのだろうか?
質問のきっかけは村上小説「ダンス・ダンス・ダンス」の羊男キャラ
小説では、羊男は次のようなことを言っていると訳されています。
「私たちが言ったように、私たちはできることをします。あなたが望むものにあなたを再接続してみてください」と羊男は言いました。「だけど一人じゃできない。お前も働かなきゃ」
したがって、一部の句読点は保持されますが、すべてではありません。人間が読むには十分ですが、やや恣意的です。
このためのパーサーを構築するための戦略は何ですか? 文字の一般的な組み合わせ、音節数、条件付き文法、先読み/後読み正規表現など?
具体的には、Python に関して、(寛容な) 翻訳フローをどのように構築しますか? 完全な答えを求めるのではなく、あなたの思考プロセスがどのように問題を分解するかを求めているだけです。
私は軽薄な方法でこれを尋ねますが、興味深い (nlp/crypto/frequency/social) 回答が得られるかもしれない質問だと思います。ありがとう!
python - Python - 英語翻訳者
英語の単語やフレーズを他の言語に翻訳するために Python でプログラムを作成する最善の方法は何ですか?
compare - 相対レーベンシュタイン距離の計算 - 理にかなっていますか?
Daitch-Mokotoff soundexing と Damerau-Levenshtein の両方を使用して、アプリケーションのユーザー エントリと値が「同じ」かどうかを調べています。
レーベンシュタイン距離は絶対値として使用することになっていますか? 20 文字の単語がある場合、4 の距離はそれほど悪くありません。単語が4文字の場合...
私が今行っているのは、距離/長さを取得して、単語の何パーセントが変更されたかをよりよく反映する距離を取得することです。
それは有効で実証済みのアプローチですか?それともただのバカですか?