問題タブ [microbenchmark]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
microbenchmark - マイクロベンチマークはどのくらい実行する必要がありますか?
まず第一に、これはマイクロベンチマークの有用性についてではありません。私はそれらの目的をよく知っています。単一の側面を強調するために、非常に特殊なケースでのパフォーマンス特性と比較を示します。これがあなたの仕事に何らかの影響を与えるべきかどうかは別の話です。
数年前、誰か(Heinz Kabutz?)は、結果を確認する価値のあるすべてのベンチマークを少なくとも数分実行する必要があり、少なくとも3回実行する必要があると指摘しましたが、最初の実行は常に破棄されます。これは、JVMのウォーミングアップ、環境の不整合(バックグラウンドプロセス、ネットワークトラフィックなど)、および測定の不正確さを説明するためでした。それは私には理にかなっており、私の個人的な経験は似たようなことを示唆していたので、私は常にこの戦略を採用しました。
ただし、多くの人(たとえば、Jeff)が、数ミリ秒(!)だけ実行され、1回だけ実行されるベンチマークを作成していることに気付きました。近年、短期間のベンチマークの精度が上がっていることは知っていますが、それでも奇妙なことに思います。ある程度有用な出力を得るために、すべてのマイクロベンチマークを少なくとも1秒間実行し、少なくとも3回実行する必要がありますか?それとも、そのルールは最近廃止されていますか?
arrays - MATLABのnumel関数とlength関数の違い
xの要素の総数をlength(x)返しmax(size(x))たり返したりすることは知っていますが、1行n列の配列にはどちらが適していますか?numel(x)それは重要ですか、それともこの場合は互換性がありますか?
編集:キックのためだけに:
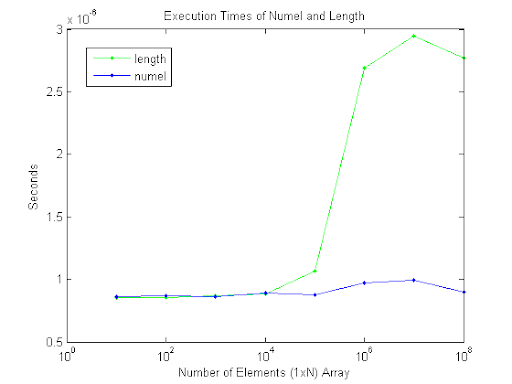
10万個の要素に到達するまで、パフォーマンス的には同じように見えます。
java - Caliper を使用するときにコマンド ラインを指定する方法は?
Google のマイクロ ベンチマーク プロジェクト Caliper は非常に興味深いと思いますが、ドキュメントはまだ (一部の例を除いて) まったく存在しません。
JVM キャリパーの起動のコマンド ラインに影響を与える必要がある 2 つの異なるケースがあります。
- いくつかの固定値を設定する必要があります (理想的にはいくつかの固定値を交互に使用します) -D パラメータ
- いくつかの固定された (理想的にはいくつかの固定値を交互に使用する) JVM パラメーターを指定する必要があります。
このような機能を追加することについての議論を見ましたが、それが追加されたかどうか、またその場合の構文はどうなったかについて結論を出すことができませんでした。
Java doc へのいくつかの例またはポインタ (これがどこかに文書化されていると仮定して) などは非常に高く評価されます!
java - ここでの「等しい」実装では、Javaは何をしますか?
今日、私は次のことに遭遇しました:
次の「等しい」メソッドを持つ2つのクラスNewClassとNewClass1について考えてみます。
NewClass:
NewClass1:
私が奇妙だと思うのは、NewClass1のequalsがNewClassのequalsよりも指数関数的に遅いように見えることです(10.000.000は3000msに対して14msを呼び出します)。最初は、これは「instanceof」チェックに関連していると思いましたが、「return equals((NewClass1)obj);」を置き換えると 「falseを返す;」NewClass1では、突然、ほぼ同じ速度で実行されます。私の意見では、equals(Object)のreturnステートメントが実際に呼び出されることはないため、ここで何が起こっているのかはよくわかりません。ここで何が間違っているのですか?
以下は、私がそこで間違いを犯した場合の私の「ベンチマークコード」です。
multithreading - NSDateFormatter の割り当てと初期化のコストを最小限に抑える方法は?
NSDateFormatterを使用すると非常にコストがかかることに気付きました。オブジェクトの割り当てと初期化にはすでに多くの時間がかかっていることがわかりました。
さらに、NSDateFormatter複数のスレッドで を使用すると、コストが増加するようです。スレッドが互いに待機しなければならないブロッキングが発生する可能性はありますか?
この問題を説明するために、小さなテスト アプリケーションを作成しました。チェックアウトしてください。
- http://github.com/johnjohndoe/TestNSDateFormatter
- git://github.com/johnjohndoe/TestNSDateFormatter.git
そのようなコストの理由は何ですか?また、使用方法を改善するにはどうすればよいですか?
17.12. - 私の観察を更新するには: 並列に処理された場合に、シリアルに実行された場合と比較して、スレッドが長く実行される理由がわかりません。時間差は、NSDateFormatter が使用されている場合にのみ発生します。
java - マイクロベンチマーク システム Java
このページの「ルール」に従って、Java でマイクロバンクマークを作成しています。最後の規則は次のように述べています。
「測定のノイズを減らします。静かなマシンでベンチマークを実行してください…」</p>
ですから、できるだけ静かなシステムを作る方法を考えています。不要なサービスを無効にした Windows 7 のクリーン インストールは、静かなシステムの良い例ですか、それともより良いオプションはありますか?
performance - フィボナッチマイクロベンチマークで C と比較して Haskell のパフォーマンスを向上させることについて
この質問に出くわしました 、フィボナッチ数の計算に関するさまざまなコンパイラのパフォーマンスを素朴な方法で比較しました。
Haskell でこれを実行して、C と比較してみました。
C コード:
結果:
ハスケル:
結果:
プロファイリング
fib100% の時間と割り当てが必要であることがわかりますが、当然のことです。ヒープのプロファイルをいくつか取りましたが、それらが何を意味するのかわかりません:


私の質問: この Haskell プログラムのパフォーマンスを C に近づけるために、私の側からできることはありますか? それとも、このマイクロベンチマークで GHC がたまたま速度を低下させる方法なのですか? (フィブを計算するための漸近的に高速なアルゴリズムを求めているわけではありません。)
どうもありがとうございました。
[編集]
ghc -O3この場合よりも高速であることが判明しましたghc -O3 -fllvm -optlo-O3。しかしoptlo-block-placement、LLVM バックエンドには明らかな違いがありました。
私がこれを調査したかった理由は、このプログラムでは C と OCaml の両方が Haskell よりも大幅に高速だったからです。私はそれを受け入れることができず、できる限りのことをすでに行っていることを確認するためにもっと学びたいと思っていました:D
scala - Scalaの可変で不変のコレクションをjava.util.concurrent。*コレクションと比較するマイクロベンチマーク
java.util.concurrentマルチスレッド環境で、Scalaの可変コレクションと不変コレクションを相互に比較し、コレクションを比較する公開されたマイクロベンチマークはありますか?サーバーサイドコードでHashMapをキャッシュするなど、リーダーがライターをはるかに上回っている場合に特に興味があります。
Clojureコレクションのマイクロベンチマークも受け入れられます。それらのアルゴリズムはScala2.8永続コレクションで使用されているものと類似しているためです。
まだ何も行われていない場合は自分で作成しますが、優れたマイクロベンチマークを作成するのは簡単ではありません。
java - ジャバ。文字列を連結します。マイクロベンチマーク
最初のステップで、次のコードを実行します。
アウト: 13579。
2 番目のステップで、次のコードを実行します。
アウト: 27328.
2 つの質問があります。
- 私の銀行印と言えますか?
- (+) と concat() のタイムラインに大きな違いがあるのはなぜですか??? 13.5秒 VS 27秒 なんで?
python - 欠損値をより簡潔に見つけるにはどうすればよいですか?
x次のコードは、とが異なる値であるかどうかをチェックしy(変数x、y、は値、、またはzのみを持つことができます)、そうである場合は 3 番目の文字に設定します。abcz
より簡潔で、読みやすく、効率的な方法でこれを行うことは可能ですか?