問題タブ [tree]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
sql - オラクル ツリー クエリでの他のテーブルの結合
次のような単純な (id、説明) テーブル t1 が与えられます。
そして、親子関係テーブルt2、
Oracle は、いくつかのカスタム構文拡張を使用して、これをツリーとしてトラバースする方法を提供しています。
正確な構文は重要ではなく、おそらく上記で間違いを犯した可能性があります。重要なことは、上記が次のようなものを生成することです
私の質問はこれです: 上記の t1 テーブルなど、sys_connect_by_path() 内の別のテーブルに参加して、次のようなものを生成することは可能ですか?
java - x、y 座標で位置を特定するためのオブジェクトの格納
特定の長方形または円内のすべてのオブジェクトをすばやく取得できるように、それぞれが x 座標値と y 座標値を持つ一連のオブジェクトを格納する高速な方法を決定しようとしています。オブジェクトの小さなセット (~100) の場合、単にそれらをリストに格納し、それを反復処理する単純なアプローチは比較的迅速です。ただし、はるかに大きなグループの場合、これは遅くなると予想されます。次のコードを使用して、x座標でソートされたツリーマップとy座標でソートされたツリーマップのペアにもそれらを格納しようとしました。
これも機能し、より大きなオブジェクトのセットの方が高速ですが、それでも思ったより遅くなります。問題の一部は、これらのオブジェクトが移動し、このストレージに挿入し直す必要があることです。これは、ツリー/リストからオブジェクトを削除して再度追加することを意味します。そこにはもっと良い解決策があるはずだと思わずにはいられません。私はこれをJavaで実装していますが、違いがあれば、解決策はより有用なパターン/アルゴリズムの形になると思います。
java - ツリー (有向非巡回グラフ) の実装
次のようなツリー/有向非巡回グラフの実装が必要です。
- いかなる種類のソートもありません。
- これ
TreeNodeは、キーと可能な値の単なるラッパーです (ノードに値を設定する必要はありません)。 - 親と子の両方へのリンクが必要です。
私のためにこれを行う標準APIやコモンズなどに何かありますか?
私はそれを自分で書いてもかまいません (そして、私は確かに皆さんにそうするように求めているわけではありません) 私は車輪の再発明をしたくないだけです.
tree - 有向非巡回グラフの強さを判断する方法は?
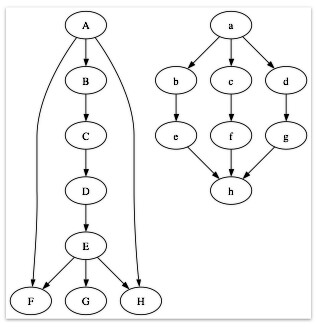
有向非巡回グラフの強度、特に特定のノードの強度を判断するための堅実なアルゴリズム/アプローチとして認識されているものは興味深いものです。これに関する主な質問は、次の 2 つのグラフに要約できます。
 (グラフが表示されない場合は、ここをクリックするか、次のリンクにアクセスしてください: http://www.flickr.com/photos/86396568@N00/2893003041/
(グラフが表示されない場合は、ここをクリックするか、次のリンクにアクセスしてください: http://www.flickr.com/photos/86396568@N00/2893003041/
私の目には、A は A よりも強い立場にあります。リンクがノックアウトされた場合に、ノードがどれだけ強く残るかで強さを判断しています. 最初のものは細い「竹馬」、2番目のものは太い「茎」と呼んでいます。
ノードの強さを判断するためにこれまでに検討したアプローチは次のとおりです。
1) 下のノードの数をカウントし、上のノードの数を引きます。
- A=7、a=7、B=5、b=1
2) 各ノードの (終端までの) 完全なパスの数を数え、それらの長さを合計します。
- A=17 (1+5+5+5+1)、B=12 (4+4+4)、a=9 (3+3+3)、b=2
- これにより、茎ではなく支柱が強くなります。
3) すべての可能なパスを数え、すべてのノードを宛先として扱います。
- A=9 (A->B、A->C、A->D、A->E、A->G、2xA->F、2xA->H)、B=6、a=9、b= 2
これまでのところ、3 が最良の選択肢のように思えますが、DAG 用に一般化された、より優れた選択肢はありますか? これは既知の最善のアプローチを持っているものですか?原則は、グラフ内のできるだけ多くの情報を使用し、解決策を直感的に説明できるようにすることです。
design-patterns - あるタイプの木構造を別のタイプに変換するための設計パターン?
マップ内のレイヤーの階層を表す一種のツリー構造があり、レイヤーの種類とカテゴリで分割されています。各ノードは、異なるタイプのレイヤーに対して異なるクラスにすることができます (ただし、すべてのノードは共通のインターフェースを実装します)。
そのクラスを ASP.NET TreeView コントロールに変換する必要があります。入力ツリーの各ノードは出力ツリーのノードであり、ノードのタイプに依存するプロパティ セットがあります。入力ツリー クラスに UI クラスを認識させたくないので、"ToTreeViewNode()" メソッドを記述できません。現在、具象ノード クラスには 4 つのタイプがあり、そのうち 2 つは複合 (子ノードを含む) で、2 つはリーフです。これは将来変更される可能性があります。
使いたくてうずうずするデザインパターンがここにあるような気がします。それが何であるかを見つけるのを手伝ってくれませんか?
c++ - 優れた安定した C++ ツリーの実装とは?
誰かが良い C++ ツリーの実装を推奨できるかどうか疑問に思っています。
記録として、私はこれまで何度もツリー アルゴリズムを作成しており、それが楽しいものであることはわかっていますが、可能であれば実用的で怠惰になりたいと思っています。したがって、実用的なソリューションへの実際のリンクがここでの目標です。
注:バランスの取れたツリーやマップ/セットではなく、一般的なツリーを探しています。この場合、内部のデータだけでなく、構造自体とツリーの接続性が重要です。したがって、各ブランチは任意の量のデータを保持できる必要があり、各ブランチは個別に反復可能でなければなりません。
mysql - mysql (階層クエリ) で任意の行数の文字列を連結する
アルバムを含む mysql テーブルがあります。各アルバムは、トップ レベルのアルバムにすることも、別のアルバムの子アルバムにすることもできます。各アルバムには、その写真が入っているフォルダーの名前であるフォルダー名があります。各アルバムには、親アルバムの ID である親と呼ばれるフィールドもあります。したがって、次のような画像へのパスがある場合:
データベースのアルバム テーブルは次のようになります。
問題は、mysql のみを使用して、このテーブルから以前に出力されたパスを取得するにはどうすればよいかということです。
algorithm - ツリーアルゴリズム
私は今日、小さなゲームのアイデアについて考えていて、それを実装する方法に出くわしました。プレイヤーは少しの効果をもたらす一連の動きをすることができますが、特定のシーケンスで行われた場合、より大きな効果をもたらすという考え方です。これまでのところ、これは私が行う方法を知っています。明らかに、私はそれをより複雑にする必要がありました(私たちはそれをより複雑にするのが好きなので)、それで私は、異なるものではありますが、両方がより大きな効果を引き起こすシーケンスの可能なパスが複数ある可能性があると思いました。また、一部のシーケンスは他のシーケンスの始まりである可能性があり、シーケンス全体でさえ他のより大きなシーケンスに含まれている可能性があります。今、私はこれを実装するための最良の方法を確かに知りません。しかし、私にはいくつかのアイデアがありました。
1)循環nリンクリストを実装できます。しかし、移動のリストは決して終わらないので、スタックオーバーフロー™を引き起こす可能性があるのではないかと心配しています。すべてのノードにn個の子があり、コマンドを受信すると、その子の1つに誘導されるか、そのようなコマンドに使用できる子がない場合は、最初に戻る可能性があります。子供が到着すると、いくつかの機能が実行され、小さな効果と大きな効果が発生します。ただし、これにより、ツリー上に多数の重複ノードが発生し、特定の移動で終了する可能性のあるすべてのシーケンスにさまざまな効果で対処できるようになる可能性があります。これは維持するのが面倒かもしれませんが、よくわかりません。理論的にのみ、コードでこれほど複雑なことを試したことはありません。このアルゴリズムは存在し、名前がありますか?それは良い考えですか?
2)ステートマシンを実装できました。次に、リンクリストをさまよっている代わりに、関数を呼び出してそれに応じてマシンの状態を更新する巨大なネストされたスイッチがあります。実装するのは簡単なようですが...まあ...面白くないようです...エレガントでもありません。巨大なスイッチはいつも私には醜いように見えますが、これはもっとうまくいくでしょうか?
3)提案?私は良いですが、私ははるかに経験が浅いです。コーディング分野の良いところは、あなたの問題がどんなに奇妙であっても、誰かが過去にそれを解決したことですが、どこを見ればよいかを知っている必要があります。誰かが私が持っていたものよりも良いアイデアを持っているかもしれません、そして私は本当に提案を聞きたかったです。
sql - フラットテーブルをツリーに解析する最も効率的/エレガントな方法は何ですか?
順序付けられたツリー階層を格納するフラット テーブルがあるとします。
ここに がある図があります[id] Name。ルート ノード 0 は架空のものです。
それを正しい順序で正しくインデントされたツリーとして HTML (またはテキスト) に出力するには、どのような最小限のアプローチを使用しますか?
さらに、基本的なデータ構造 (配列とハッシュマップ) しかなく、親/子の参照を持つ派手なオブジェクトはなく、ORM もフレームワークもなく、両手だけしかないと仮定します。テーブルは結果セットとして表され、ランダムにアクセスできます。
疑似コードまたは平易な英語で問題ありません。これは純粋に概念上の問題です。
おまけの質問: このようなツリー構造を RDBMS に格納する根本的に優れた方法はありますか?
編集と追加
あるコメント投稿者 ( Mark Besseyさん) の質問に答えるには: ルート ノードは必要ありません。とにかく表示されることはないからです。ParentId = 0 は、「これらがトップ レベルであること」を表すための規則です。Order 列は、同じ親を持つノードがどのようにソートされるかを定義します。
私が話した「結果セット」は、ハッシュマップの配列として描くことができます (その用語にとどまります)。私の例では、すでにそこにあるはずでした。いくつかの答えは、さらに一歩進んで最初に構築しますが、それは問題ありません。
ツリーの深さは任意です。各ノードは N 個の子を持つことができます。ただし、「何百万ものエントリ」ツリーを念頭に置いているわけではありません。
私が選んだノード名 ('Node 1.1.1') を信頼できるものと間違えないでください。ノードは、'Frank' または 'Bob' と同じように呼ぶことができます。命名構造は暗示されていません。これは単に読みやすくするためです。
独自のソリューションを投稿したので、皆さんはそれをバラバラにすることができます。
database - ネストされた集合モデルを使用して保存されたツリーをどのようにソートしますか?
ネストされたセット モデルとは、ここで説明されていることを意味します。
ユーザー定義の階層に「カテゴリ」を格納するための新しいシステムを構築する必要があります (より適切な言葉は思いつきません)。ネストされたセット モデルは、書き込みではなく読み取り用に最適化されているため、それを使用することにしました。残念ながら、ネストされたセットの調査とテスト中に、ソートされたノードを持つ階層ツリーをどのように表示するかという問題に遭遇しました。たとえば、階層がある場合:
次のように表示されるように並べ替えます。
捏造が研究の前に現れることに注意してください。
とにかく、長い検索の結果、「ツリーを多次元配列に格納してソートする」、「ツリーを再ソートし、ネストされたセットモデルにシリアル化する」などの回答が表示されました(言い換えています...)。いずれにせよ、最初の解決策は RAM と CPU の恐ろしい浪費であり、どちらも非常に有限のリソースです。2 番目の解決策は、多くの面倒なコードのように見えます。
とにかく、(ネストされたセットモデルを使用して)方法を理解することができました:
- SQL で新しいツリーを開始する
- ツリー内の別のノードの子としてノードを挿入します
- ツリー内の兄弟ノードの後にノードを挿入します
- SQL から階層構造を持つツリー全体をプルする
- 深さの制限の有無にかかわらず、階層内の特定のノード (ルートを含む) からサブツリーをプルします
- ツリー内の任意のノードの親を見つける
したがって、#5 と #6 を使用して、必要な並べ替えを行うことができ、並べ替えられた順序でツリーを再構築するためにも使用できると考えました。
しかし、私が学んだことをすべて見てきたので、#3、#5、および #6 を一緒に使用して、ソートされた挿入を実行できることがわかりました。ソートされた挿入を行った場合、常にソートされます。ただし、並べ替え基準を変更したり、別の並べ替え順序が必要な場合は、振り出しに戻ります。
これは、ネストされたセット モデルの制限でしょうか? その使用は、出力のクエリソートを阻害しますか?