問題タブ [utf-32]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
c++ - Linuxのコンソールに出力される国際UTF-32文字列
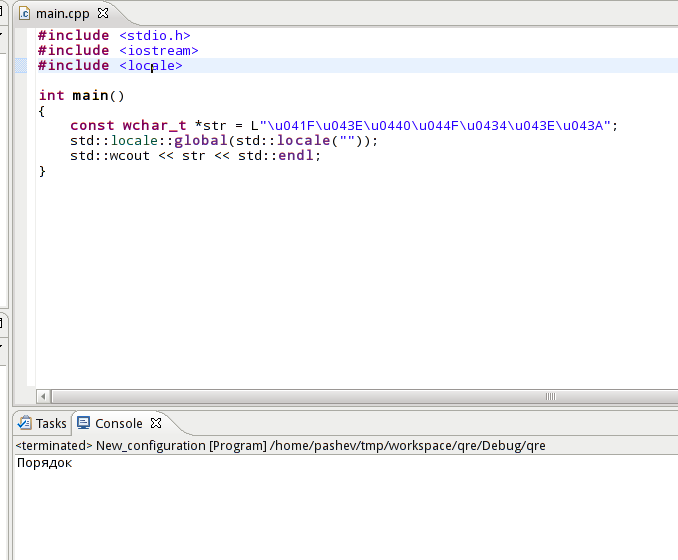
これは、UTF-32wchar_t文字列でロシア語のフレーズを次のように出力するコードです。
- 正しいもの:Ubuntu11.10のUTF- 8gnomeターミナルから実行した場合のПорядок
- 上記のテスト実行でのEclipseのРџРѕСЂСЏРґРѕРє
- 45 = B8D8:0B> @ Eclipseの実際のプログラム(誰がどこで何をしているのかさえわかりませんが、誰かがロケールを台無しにしていると思います)
- ??????? ロケールを呼び出さない場合
- strは、Eclipse WatchウィンドウにDetails:0x400960 L "\ 320 \ 237 \ 320 \ 276 \ 321 \ 200 \ 321 \ 217 \ 320 \ 264 \ 320 \ 276 \ 320\272"として表示されます。
- EclipseメモリウィンドウではASCIIのみのバイト文字として表示されます(これがUTF-32文字列であることを指定する方法はありません)
これは、Eclipseコンソールまたはプログラムのいずれかの設定ミスであると思います。たとえば、Eclipseで私のコードを実行しただけの人は、正しい出力を表示するからです。
{kind=link}
誰かがこの混乱に光を当てることができますか?UTF-32 wchar_t文字列に格納されている国際シンボルを出力するためにすべての部分(OS、gcc、ターミナル、Eclipse、ソースなど)をセットアップする正しい方法は何ですか?
ちなみに、UTF-32を使用しているのに、なぜこれらすべてに注意を払う必要があるのでしょうか。それで、内部に何があるかを知ることができます...
c# - UTF32 と C# の問題
そのため、文字エンコーディングに問題があります。次の 2 文字を UTF32 でエンコードされたテキスト ファイルに入れると、次のようになります。
そして、それらに対して次のコードを実行します。
私は得る:
(同じ文字が 2 回、つまり入力ファイル != 出力)
最初の文字の 16 進数:
15 9E 02 00
そして2番目に:
15 9E 00 00
テキスト ファイルの作成には gedit を使用し、C# には mono を使用し、Ubuntu を使用しています。
入力ファイルまたは出力ファイルのエンコーディングを指定するかどうかも問題ではありません。UTF32 エンコーディングの場合は気に入らないだけです。入力ファイルが UTF-8 エンコーディングの場合に機能します。
入力ファイルは次のとおりです。
FF FE 00 00 15 9E 02 00 0A 00 00 00 15 9E 00 00 0A 00 00 00
それはバグですか、それとも私だけですか?
ありがとう!
unicode - なぜUTF-24がないのですか?
重複の可能性:
すべての文字をエンコードするのに 21 ビットしか必要ないのに、なぜ UTF-32 が存在するのですか?
Unicode の最大コード ポイントは、UTF-32 で 0x10FFFF です。UTF-32 には、21 の情報ビットと 11 の余分な空白ビットがあります。では、各コード ポイントを 4 バイトではなく 3 バイトで格納するための UTF-24 エンコーディング (つまり、上位バイトが削除された UTF-32) がないのはなぜでしょうか?
c++ - UTF-8 から UTF-32 への変換、それぞれの「文字」数の事前計算
UTF-8 文字列を UTF-32 文字列に変換するアルゴリズムは動作していますが、事前に UTF-32 文字列にすべてのスペースを割り当てる必要があります。UTF-8 文字列が占める UTF-32 の文字数を知る方法はありますか。
たとえば、UTF-8 文字列 "¥0" は 3 文字であり、UTF-32 に変換されると 2 つの unsigned int になります。変換を行う前に必要な UTF-32 の「文字」の数を知る方法はありますか? それとも、アルゴリズムを書き直す必要がありますか?
utf-8 - Utf8_general_ciまたはutf8mb4または...?
utf16またはutf32?多くの言語でコンテンツを保存しようとしています。一部の言語は倍幅フォントを使用します(たとえば、日本語フォントは英語フォントの2倍の幅であることがよくあります)。どの種類のデータベースを使用すべきかわかりません。これらの4つの文字セットの違いに関する情報...
java - Java 7 の内部文字エンコーディング
私の知る限り、JRE が Java アプリケーションを実行すると、文字列は内部的に USC2 バイト配列として認識されます。ウィキペディアでは、次のコンテンツを見つけることができます。
Java はもともと UCS-2 を使用していましたが、J2SE 5.0 で UTF-16 補助文字サポートを追加しました。
Java (Java 7) の新しいリリース バージョンでは、その内部文字エンコーディングは何ですか?
Java が内部で UCS-4 を使用し始める可能性はありますか?
c# - 内部にサロゲート ペアを含む文字列を作成するにはどうすればよいですか?
Jon Skeet のブログで、文字列の反転について語っているこの投稿を見ました。彼が自分で示した例を試してみたかったのですが、うまくいくようです...実際に文字列の反転を失敗させるサロゲートペアを含む文字列を作成する方法がわからない. 自分で失敗を確認できるように、サロゲート ペアを含む文字列を実際に作成するにはどうすればよいでしょうか。
javascript - 「高い」ユニコード文字を含む文字列を、utf-32 (「実際の」) コードから派生した 10 進値で構成される配列に変換することは可能ですか?
(理論的には可能) 文字列で動作するこのスクリプトを見てください。
「55349,56421,56204,56800,65,56288,56689」の代わりに、「119909,995808,65,1081713」を取得できますか? more- utf -32-aware-javascript-stringとQ: UTF-16 から文字コードに変換するアルゴリズムは何ですか? + Q: もっと簡単な方法はありませんか? unicode.org/faq/utf_bomからですが、この情報の使い方がわかりません。
utf-8 - C++11でのUTF-8の読み取り/書き込み/印刷
私はC++11の新しいUnicode機能を調査してきましたが、他のC ++ 11エンコーディングの質問は非常に役立ちましたが、 cppreferenceの次のコードスニペットについて質問があります 。コードは、UTF-8エンコーディングで保存されたテキストファイルを書き込み、すぐに読み取ります。
私の質問は非常に単純ですが、なぜループにwchar_t必要なのですか?for文字u8列リテラルは単純なものを使用して宣言できchar *、UTF-8エンコーディングのビットレイアウトはシステムに文字の幅を通知する必要があります。UTF-8からUTF-32への自動変換があるようです(したがってwchar_t)が、その場合、なぜ変換が必要なのですか?