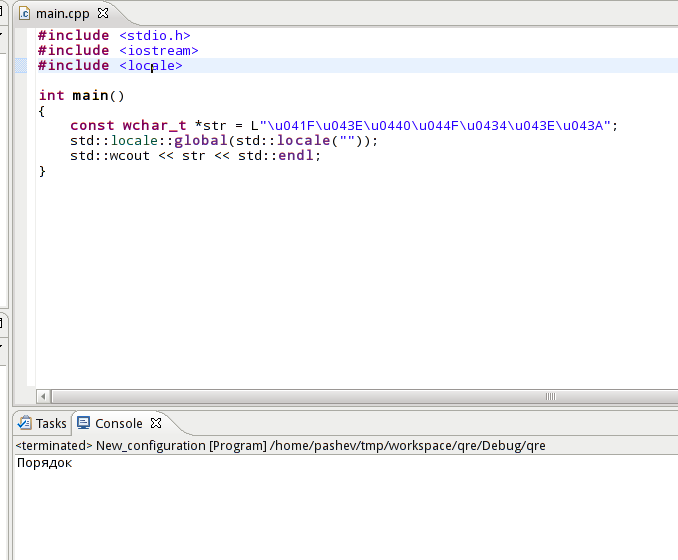
#include <stdio.h>
#include <iostream>
#include <locale>
int main()
{
const wchar_t *str = L"\u041F\u043E\u0440\u044F\u0434\u043E\u043A";
std::locale::global(std::locale(""));
std::wcout << str << std::endl;
}
これは、UTF-32wchar_t文字列でロシア語のフレーズを次のように出力するコードです。
- 正しいもの:Ubuntu11.10のUTF- 8gnomeターミナルから実行した場合のПорядок
- 上記のテスト実行でのEclipseのРџРѕСЂСЏРґРѕРє
- 45 = B8D8:0B> @ Eclipseの実際のプログラム(誰がどこで何をしているのかさえわかりませんが、誰かがロケールを台無しにしていると思います)
- ??????? ロケールを呼び出さない場合
- strは、Eclipse WatchウィンドウにDetails:0x400960 L "\ 320 \ 237 \ 320 \ 276 \ 321 \ 200 \ 321 \ 217 \ 320 \ 264 \ 320 \ 276 \ 320\272"として表示されます。
- EclipseメモリウィンドウではASCIIのみのバイト文字として表示されます(これがUTF-32文字列であることを指定する方法はありません)
これは、Eclipseコンソールまたはプログラムのいずれかの設定ミスであると思います。たとえば、Eclipseで私のコードを実行しただけの人は、正しい出力を表示するからです。
{kind=link}
誰かがこの混乱に光を当てることができますか?UTF-32 wchar_t文字列に格納されている国際シンボルを出力するためにすべての部分(OS、gcc、ターミナル、Eclipse、ソースなど)をセットアップする正しい方法は何ですか?
ちなみに、UTF-32を使用しているのに、なぜこれらすべてに注意を払う必要があるのでしょうか。それで、内部に何があるかを知ることができます...