問題タブ [utf-8]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
iphone - iPhone「Webサイトエラー」
iPhone アプリ用に PHP でサーバー側プログラムを作成しています。そして、私はiPhoneを持っていません。:P
iPhone アプリは、ユーザーが iPhone アプリを実行するたびに、サイトから XML ファイルを要求します。XML ファイルについては、http ://www.appvee.com/iphone/adsまたはhttp://www.appvee.com/iphone/latestにアクセスしてください。
また、メッセージ ボックスに次のエラー メッセージが表示されます。
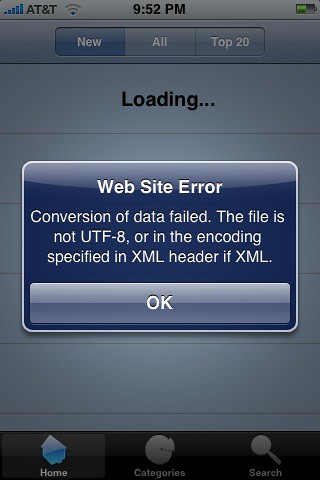
おそらく、header("Content-type: text/xml"); を追加する必要があります。PHPファイルの先頭に?私はこの行を追加しませんでしたが、以前はうまく機能していました。
どんな助けでも大歓迎です。
python - Pythonでファイルをutf-8に変換するには?
Python で一連のファイルを utf-8 に変換する必要がありますが、「ファイルの変換」の部分で問題が発生しています。
私は同等のことをしたい:
ありがとう!
ruby-on-rails - act_as_taggable_on_steroids の Unicode の問題
フランス語の文字を含むタグを使用してブログを実装しています。私の質問は、URL 内のスペースと Unicode (utf-8) 文字を処理する方法に関するものです。
ohlàlà! というタグがあるとします。タグクラウドに次のコードがあります。
この問題にどう対処すればよいですか?
utf-8 - UTF-8 文字列を反転するにはどうすればよいですか?
最近、誰かがC で文字列を逆にするアルゴリズムについて尋ねました。提案されたソリューションのほとんどは、非シングルバイト文字列を扱うときに問題がありました。そこで、特に utf-8 文字列を処理するための優れたアルゴリズムは何かと考えていました。
私は答えとして投稿しているコードを思いつきましたが、他の人のアイデアや提案を見てうれしいです. 私は実際のコードを使用することを好んだので、このサイトで最も人気のある言語の 1 つと思われる C# を選択しましたが、コードが別の言語であっても、合理的である限り気にしません。命令型言語に精通している人なら誰でも理解できます。そして、これはそのようなアルゴリズムを低レベルで実装する方法を確認することを目的としているため (低レベルとは単にバイトを処理することを意味します)、コア コードにライブラリを使用しないようにするという考えです。
ノート:
私はアルゴリズム自体、そのパフォーマンス、および最適化方法に興味があります (i++ を ++i などに置き換えるのではなく、アルゴリズムレベルの最適化を意味します。実際のベンチマークにもあまり興味がありません)。
実際に製品コードや「車輪の再発明」で使用するつもりはありません。これは単なる好奇心と練習用です。
私は C# バイト配列を使用しているので、NUL が見つかるまで文字列を実行せずに文字列の長さを取得できると想定しています。つまり、文字列の長さを見つける複雑さを説明していません。ただし、たとえば C を使用している場合は、コア コードを呼び出す前に strlen() を使用することで、それを除外できます。
編集:
Mike F が指摘しているように、私のコード (およびここに投稿された他の人のコード) は合成文字を扱っていません。ここにあるものについての情報。私はその概念に精通していませんが、それが「組み合わせ文字」、つまり他の「ベース」文字/コードポイントとの組み合わせでのみ有効な文字/コードポイントがあることを意味する場合、そのようなルックアップテーブル文字を使用して、反転時に「グローバル」文字 (「ベース」+「結合」文字) の順序を維持できます。
file - Unicode ファイルのバイト オーダー マーカーを設定するにはどうすればよいですか?
これが「実際の」プログラミングの質問ではないことはわかっています。でも、それはプログラミングに関係するので、とにかく設定します。ファイルのバイト オーダー マーカーを読み取って、それが utf-8 か utf-16 かを確認するテストが必要なプログラムがあります。私の問題は、バイト オーダー マーカーを設定できるプログラム/テキスト エディターが見つからないことです。これをテキストファイルに設定する方法を誰か教えてもらえますか?
mysql - MySQL が UTF-8 を適切に処理するようにする方法
昨日私が行った質問への回答の 1 つは、データベースが UTF-8 文字を正しく処理できることを確認する必要があることを示唆していました。MySQLでこれを行うにはどうすればよいですか?
perl - 不正な UTF 文字を検出する方法
SQL*Loader を使用してデータをロードする際に、Perl スクリプトを使用して不正な UTF-8 文字を検出し、空白に置き換えたいと考えています。これどうやってするの?
c++ - 4 バイトの UTF-8 文字を入力するにはどうすればよいですか?
さまざまなバイト長の utf-8 文字でテストする必要がある小さなアプリを作成しています。
たとえば、次のようにして、1、2、および 3 バイトの utf-8 でエンコードされた Unicode 文字を入力してテストできます。
しかし、どうすれば 4 バイトでエンコードされた Unicode 文字を取得できますか? 私が試してみました:
私が理解している限り、出力する必要があります。しかし、それを印刷するとᴶ0になります
私は何が欠けていますか?
編集:
先行ゼロを追加して動作させました:
もっと早く考えていればよかったです:)
php - BOM で UTF-8 ファイルを検索するエレガントな方法は?
デバッグの目的で、UTF-8 バイト オーダー マーク (BOM) で始まるすべてのファイルのディレクトリを再帰的に検索する必要があります。私の現在の解決策は、単純なシェル スクリプトです。
または、短くて読めないワンライナーを好む場合は、次のようにします。
改行を含むファイル名では機能しませんが、そのようなファイルは想定されていません。
より短い、またはよりエレガントなソリューションはありますか?
興味深いテキスト エディターまたはテキスト エディター用のマクロはありますか?
unicode - UTF-8テキストエディタを探しています
同じドキュメント内の異なるエンコーディングのテキストを処理できる(シンプルな)テキストエディタを探しています。
日本語と英語のテキストが混在するサイトを開発する必要がありますが、現在(英語のWindowsシステムで)使用しているエディターは日本語のテキストを表示できません。Jeditファイルには入力した日本語のテキストが表示されませんが、ブラウザでファイルを見ると正しく表示されます。Gvimは、エディタとブラウザにすべての日本語テキストを疑問符として表示します。Gvimでは漢字を入力すると機能します(発音を入力してからスペースバーを押して漢字を取得します)が、希望する漢字を確認すると、その漢字が疑問符に置き換えられます。(漢字ごとに1つの疑問符)。
utf-8でエンコードされたテキストを表示し、utf-8ファイルとして保存できるhtmlおよびphpファイルを編集するためのテキストエディターを誰かに勧めてもらえますか?
ありがとうございました。
emacsについて読んだ後、私はそれをインストールしました。下記参照。
ヒントをありがとう。Unicodeフォントをまだ持っていない場合は、オンラインで見つけるか購入する必要があります。Windowsシステムにフォントをインストールする手順は次のとおりですhttp://support.microsoft.com/kb/314960
jEdit JeditのフォントをUTFフォントに変更したところ、日本語が正常に表示されるようになりました。何を入力しているのかわからないので、日本語の入力にはまだ問題があります。(フォントを変更してファイルを編集するには、[ユーティリティ]->[グローバルオプション]->[テキスト領域]に移動してUnicodeフォントを選択すると、日本語の文字が表示されます。
gVim私はまだgvimでフォントを追加する方法を理解しようとしています。その方法がわかったら、これを更新します。
EmacsEmacsは漢字を正しく表示しません。???として表示されます。でも、少なくとも日本語で何を入力したかがわかり、正しい単語を選択できます。
したがって、この時点で、jEditでは日本語のテキストは表示されますが、日本語のテキストは入力できません。Gvim日本語のテキストを入力できますが、テキスト領域内に???と表示されます。同じことがEmacsにも当てはまります。emacsとgvimにフォントを追加することは、悲しいことに簡単な作業ではありません。現在、Arial unicode MSフォントでメモ帳を使用し、日本語エディターとしてUTF-8ファイルとして保存しています。理想的ではありませんが、少なくとも機能します。